Sentiment analysis en críticas de películas mediante regresión logística
¿Qué es el análisis de sentimiento?
El sentimiento de análisis (sentiment analysis en inglés) es una subdisciplina del campo procesamiento del lenguaje natural (NLP en inglés) bastante común y que nos permite identificar la opinión emocional que hay detrás de un texto, es decir, si es positivo, negativo o neutro.
Como podéis imaginaros, esta técnica tiene innumerables aplicaciones debido a su gran utilidad. Por ejemplo, el análisis de sentimientos podría ayudar a una empresa a entender el sentimiento que provoca su marca, producto o servicio aplicándolo a los tweets en los que son mencionados.
Para este tutorial nos hemos basado en el ejemplo práctico que aparece en el capítulo 8 del fantástico libro Python Machine Learning, donde utilizan 50.000 críticas de películas altamente polares del sitio web IMDb para construir un clasificador capaz de identificar si una crítica de una película tiene un sentimiento positivo o negativo.
En el presente tutorial, vamos a trabajar con un conjunto de datos consistente en 4.800 críticas de usuarios de la página web de votación y recomendación de películas filmaffinity (www.filmaffinity.com) para posteriormente construir un modelo de regresión logística capaz de distinguir entre reseñas positivas y negativas.
Extrayendo las críticas de usuarios de filmaffinity
Como hemos mencionado antes, en este tutorial, vamos a utilizar un conjunto de datos consistente en 4.800 críticas de usuarios y sus puntuaciones correspondientes de la página web de filmaffinity. Filmaffinity es una web de recomendación de películas y series donde los usuarios pueden escribir y compartir sus propias reseñas de cada película junto con una valoración numérica que puede ir del 1 al 10.
De las críticas extraídas, la mitad (2.400) tiene una puntuación por debajo del 5 y la otra mitad (2.400) tiene una nota superior a 6. Por lo tanto, entre el conjunto de datos no hay críticas neutras con puntuaciones de 5 o 6.
Para realizar la extracción de críticas hemos implementado un rastreador web usando el framework Scrapy de Python que se encarga de extraer y almacenar las críticas junto con la valoración numérica. Si tenéis curiosidad sobre como implementar un rastreador de este tipo en Python, echar un vistazo a esta publicación, donde mostramos como extraer paso a paso con Scrapy los datos de un sitio web.
Posteriormente, hemos exportado esa información como un fichero CSV que podéis descargar desde nuestra cuenta de Github, aquí.
Una vez ya tenemos nuestros datos preparados, estamos listos para etiquetar las críticas como positivas (1) o negativas (0) basandonos en su puntuación y que de esta manera nuestro modelo de predicción pueda clasificarlas. ¡Empecemos!
Carga y etiquetado de las críticas
Una vez ya hemos recopilado las 4.800 críticas con los que vamos a entrenar nuestro modelo de clasificación, debemos etiquetar cada crítica como positiva (1) o negativa (0) a partir de su puntuación.
El objetivo es construir un modelo de regresión logística capaz de predecir a qué clase o etiqueta pertenecerá una nueva crítica. En nuestro caso, se trata de un modelo de clasificación binaria (positivo o negativo) aunque también es posible indicar y predecir el grado de positividad o negatividad que tiene cada texto.
Antes de nada, importamos las librerías que vamos a necesitar a lo largo del tutorial:
import pandas as pd
import numpy as np
import json
import re
import eli5
from nltk.corpus import stopwords
from nltk.stem import SnowballStemmer
from nltk.tokenize import ToktokTokenizer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import KFold
from sklearn.metrics import confusion_matrix
Lo siguiente que debemos hacer es cargar nuestro fichero CSV con las críticas, puntuaciónes y URLs de cada película de filmaffinity y convertirlo en un objeto DataFrame mediante la función read_csv que nos proporciona la librería pandas. Una vez hemos construido nuestro DataFrame, mostramos las primeras cinco observaciones mediante la función head para asegurarnos de que se han cargado los datos de manera correcta:
# Cargamos el fichero con las críticas y su puntuación
df = pd.read_csv("./data/criticas.csv")
# Mostramos las primeras 5 observaciones
df.head()
Después, etiquetamos las críticas como positivas (1) o negativas (0); una reseña negativa tiene una puntuación por debajo de 5, y una reseña positiva tiene una puntuación superior a 6. Por lo tanto, las reseñas con valoraciones más neutras no se han incluido en el conjunto de datos. Además, no se han incluido más de 30 reseñas de una misma película.
Para realizar el etiquetado de los datos, hemos creado una nueva variable binaria llamada sentiment, la cuál será nuestra variable a predecir y contendrá un 1 si se trata de una crítica positiva y un 0 en caso contrario. En el siguiente código vemos como crear de forma sencilla esta variable a partir de la nota asignada a cada película:
# Creamos una variable con el sentimiento
# Si puntuación > 6 -> 1
# Si puntuación < 5 -> 0
df['sentiment'] = np.where(df['nota'] > 6, 1, 0)
Seguidamente eliminamos las variables nota y url, que no utilizaremos en el entrenamiento de nuestro modelo, y mostramos de nuevo las primeras 5 observaciones:
# Eliminamos las variables nota y url
df.drop(columns=["nota","url"], inplace=True)
df.head()
Una vez tenemos nuestro objeto DataFrame definitivo, vamos a implementar diversos métodos que se encargarán de la limpieza y preprocesamiento de los datos.
En el siguiente código implementamos los métodos necesarios para llevar a cabo estas tareas:
tokenizer = ToktokTokenizer()
STOPWORDS = set(stopwords.words("spanish"))
stemmer = SnowballStemmer("spanish")
def limpiar_texto(texto):
"""
Función para realizar la limpieza de un texto dado.
"""
# Eliminamos los caracteres especiales
texto = re.sub(r'\W', ' ', str(texto))
# Eliminado las palabras que tengo un solo caracter
texto = re.sub(r'\s+[a-zA-Z]\s+', ' ', texto)
# Sustituir los espacios en blanco en uno solo
texto = re.sub(r'\s+', ' ', texto, flags=re.I)
# Convertimos textos a minusculas
texto = texto.lower()
return texto
def filtrar_stopword_digitos(tokens):
"""
Filtra stopwords y digitos de una lista de tokens.
"""
return [token for token in tokens if token not in STOPWORDS
and not token.isdigit()]
def stem_palabras(tokens):
"""
Reduce cada palabra de una lista dada a su raíz.
"""
return [stemmer.stem(token) for token in tokens]
def tokenize(texto):
"""
Método encargado de realizar la limpieza y preprocesamiento de un texto
"""
text_cleaned = limpiar_texto(texto)
tokens = [word for word in tokenizer.tokenize(text_cleaned) if len(word) > 1]
tokens = filtrar_stopword_digitos(tokens)
stems = stem_palabras(tokens)
return stems
Primeramente, el método limpiar_texto realiza una limpieza inicial de los textos, eliminando los caracteres especiales como ¿ o ¡, las palabras con un solo carácter que normalmente no contienen información útil y convirtiendo todo a minúsculas entre otras tareas.
Después, llega el turno del proceso de tokenización, que consiste en dividir los textos en tokens o palabras individuales.
Posteriormente, eliminamos las stopwords que componen los textos, es decir, las palabras comunes que no aportan significado, como yo, el o y. Previamente debemos descargar la lista de stopwords en castellano mediante el comando stopwords.words("spanish").
Una vez hemos eliminado las stopwords, reducimos cada palabra a su raíz mediante el proceso de stemming.
Como podéis observar, la función tokenize será la encargada de ir llamando al resto de métodos para llevar a cabo el preprocesamiento de los datos de principio a fin. Esta función se le pasará más adelante al objeto TfIdfVectorizer, encargado de representar el texto mediante vectores numéricos listo para entrenar el modelo.
Pero antes, debemos dividir los datos en un conjunto de entrenamiento (67%) y un conjunto de test (33%). Para ello, usamos el método train_test_split que nos proporciona la librería scikit-learn pasandole como parámetros la variable con los textos de la críticas (X) y el sentimiento de las mismas que queremos predecir (y).
Adicionalmente, para asegurarnos de que la distribución de la variable a predecir es similar en los dos conjuntos de datos (train y test), utilizamos el parámetro stratify indicándole cual es la variable respuesta:
# Dividimos los datos en train y test
X = df.critica
y = df.sentiment
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33,
stratify=y, random_state=42)
A continuación, comprobamos que ambos conjuntos de datos contienen el mismo porcentaje de cada clase:
# Comprobamos que train y test contienen el mismo porcentaje de cada clase en y
print(len(y_train[y_train == 0]) / 3224)
len(y_test[y_test == 0]) / 1588
Como podemos apreciar, la distribución es similar en los dos casos.
Representando los textos de manera numérica mediante la técnica tf-idf
El siguiente paso consiste en aplicar el algoritmo tf-idf (del inglés Term frequency – Inverse document frequency) a nuestros textos para representarlos mediante vectores numéricos. A diferencia del modelo de bag-of-words (BOW) que vimos en la publicación de topic modeling, esta técnica refleja la importancia de cada palabra en un documento.
El valor tf-idf de una palabra en un documento se calcula multiplicando dos métricas diferentes que explicaremos a continuación:
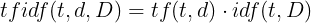
El tf(t, d) es la frecuencia del término y la opción más simple para calcularlo consiste en utilizar el número de veces que el término t ocurre en el documento d. Otra opción llamada frecuencia escalada logarítmicamente es la siguiente:
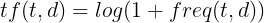
Por otro lado, idf(t, D) es la frecuencia inversa de documento y nos indica si la palabra es común o no en la colección de documentos. Cuanto más se acerque a 0, más común es la palabra. Se calcula dividiendo el número total de documentos entre el número de documentos que contienen una palabra y calculando el logaritmo. La fórmula es la siguiente:
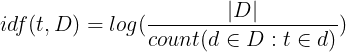
Donde D es el número total de documento y el denominador es el número de documentos d que contienen el término t.
Una vez tenemos las anteriores dos métricas, podemos calcular el valor tf-idf de cada palabra. Las palabras con un valor más alto son más importantes, y las que tienen un valor más baja son menos importantes. Por ejemplo, cuando una palabra se encuentra en muchos documentos, el resultado de la división dentro del logaritmo se acerca a 1 y, por lo tanto, el valor del tf-idf será cercano a 0.
Para poder aplicar esta técnica en Python, la librería scikit-learn nos proporciona el objeto TfidfVectorizer, al cual le pasamos como parámetro el método tokenize que hemos visto antes y que se encarga de realizar el preprocesamiento de los textos antes de transformarlos en tf-idfs. Veamos como creamos el objeto y lo ajustamos con los datos de entrenamiento:
tfidf = TfidfVectorizer(
tokenizer=tokenize,
max_features=20000)
tfidf.fit(X_train)
Es importante que lo ajustemos únicamente con el conjunto de datos de entrenamiento y luego lo utilizamos para transformar el conjunto de entrenamiento y el de test. De esta manera nos aseguramos que ninguna información del conjunto de test pueda influir en el ajuste del modelo.
En el siguiente código transformamos los dos conjuntos:
X_train = tfidf.transform(X_train)
X_test = tfidf.transform(X_test)
print(X_train.shape)
print(X_test.shape)
Optimización de hiperparámetros y entrenamiento del modelo
Ha llegado la hora de entrenar nuestro modelo de regresión logística para clasificar las reseñas de películas. Para ello, empleamos una estrategia grid search para realizar una búsqueda exhaustiva evaluando todas las combinaciones de parámetros con el objetivo de encontrar el mejor modelo.
Grid search es una técnica de optimización de hiperparámetros en el que se prueban todas las combinaciones posibles. A continuación, los modelos se evalúan mediante validación cruzada y se considera que el modelo con mayor accuracy (en nuestro caso) es el mejor.
Para utilizar esta estrategia, scikit learn nos proporciona el objeto GridSearchCV al que le debemos pasar como input el modelo de predicción y un diccionario con los parámetros (llamado search space) a optimizar. Este diccionario debe contener los nombres de parámetros como claves y las listas de ajustes de parámetros a probar como valores.
En nuestro caso queremos probar distintos valores del parámetro C, que añade regularización al modelo para reducir el overfitting, y el parámetro penalty para probar distintos tipos de regularización (Lasso y Ridge en nuestro caso).
En el siguiente código implementamos tanto el modelo de regresión logística como el search space:
# Diccionario con nombres de parámetros como claves y listas
# de ajustes de parámetros a probar como valores
parameters = {'penalty':('l1', 'l2'), 'C':[100, 10, 1.0, 0.1, 0.01]}
# Modelo de Regresión logistica
lr = LogisticRegression(random_state=42, solver='liblinear')
Además, el objeto GridSearchCV contiene el argumento cv que permite especificar el número de bloques en los que se divide los datos para la validación cruzada. También podemos pasarle un objeto de tipo KFold como el del siguiente ejemplo, al cuál le indicamos el número de bloques mediante el parámetro n_splits y mezclamos los datos ajustando el parámetro shuffle a True:
# Objecto KFold para dividir un conjunto de datos en 10 bloques
cv = KFold(n_splits=10, shuffle=True, random_state=42)
Una vez ya tenemos todas las piezas, podemos construir el GridSearchCV pasándole el objeto KFold, el modelo y el search space:
# GridSearchCV para la búsqueda de los mejores parámetros
clf = GridSearchCV(lr, parameters,
scoring='accuracy',
cv=cv,
refit=True,
verbose=2,
n_jobs=-1)
Como podéis ver, empleamos el accuracy como criterio de evaluación.
Ahora ya podemos ajustar el GridSearchCV pasandole los datos de entrenamiento:
clf.fit(X_train, y_train)
Una vez evaluados los modelos, mostramos los mejores parámetros encontrados y el accuracy del mejor modelo:
print('Mejor combinación de parámetros: %s ' % clf.best_params_)
print('CV Accuracy: %.3f' % clf.best_score_)
El accuracy del mejor modelo, ajustando el parámetro C a 10 y usando una regularización de tipo l2, es de 86,4%, ¡nada mal!
A continuación, obtenemos el mejor modelo reentrenado mediante el atributo best_estimator_ y realizamos la evaluación con los datos de test:
best_clf = clf.best_estimator_
print('Test Accuracy: %.3f' % best_clf.score(X_test, y_test))
Vemos que el valor de la métrica es muy similar a la obtenida anteriormente, por lo que podemos decir que nuestro modelo no sufre de sobreajuste.
Ahora mostramos la matriz de confusión para comprobar el rendimiento de nuestro modelo en cada clase:
y_pred = best_clf.predict(X_test)
confusion_matrix(y_test, y_pred)
En la matriz de confusión podemos ver que 117 reseñas positivas han sido clasificados incorrectamente como negativas (Falsos negativos). Además, 107 críticas negativas ha sido clasificado como positivas (falso positivo).
Finalmente, usamos la función show_weigths de la librería eli5 para visualizar el peso o impacto promedio asociado a cada variable (palabra) en nuestro modelo de regresión logística.
eli5.show_weights(estimator=best_clf,
feature_names= list(tfidf.get_feature_names()),
top=(10, 10))
En la anterior tabla, podemos ver las 10 palabras mas importantes para el modelo en cada dirección (criticas positivas y negativas).
Esto ha sido todo por hoy. Con este tutorial, hemos aprendido a aplicar sentiment analysis mediante un modelo de regresión logística para distinguir entre reseñas de películas positivas y negativas.
En futuras publicaciones os mostraremos a utilizar técnicas más avanzadas de sentiment analysis. Hasta entonces, esperamos que este tutorial os resulte de utilidad y recordad que el notebook con el código utilizado hasta ahora lo podéis descargar aquí.


















