AutoML: creación de un modelo de análisis de sentimiento con Google Cloud AutoML
El ciclo de vida de un proyecto típico de Machine Learning es iterativo y está compuesto de diversas fases, entre las que destacan la limpieza y preprocesamiento de los datos, la extracción y selección de características, la elección del modelo, el ajuste de hiperparámetros, el entrenamiento del modelo, la validación del modelo y, por último, el despliegue.
Comúnmente, cuando estamos llevando a cabo un proyecto de Machine Learning, gran parte del tiempo se emplea en tareas manuales y repetitivas. Así, de acuerdo con una encuesta realizada en Kaggle sobre el tiempo empleado en cada una de las fases de un proyecto de ciencia de datos, los profesionales dedican de media un 23% del tiempo a la limpieza de los datos y un 21% en la selección y construcción del modelo.
En este artículo explicaremos en que consiste el AutoML, que nos permite automatizar varias partes (o incluso todas) del proceso de Machine Learning y cuando es aconsejable aplicarlo. Finalmente, mostraremos un tutorial donde aplicaremos el producto AutoML ofrecido por Google (Cloud AutoML) para realizar una tarea de sentiment analysis donde construiremos un clasificador capaz de identificar si una crítica de una película tiene un sentimiento positivo o negativo.
AutoML para automatizar el proceso de Machine Learning
El aprendizaje automático automatizado (conocido como AutoML) es el campo de estudio que se ocupa de los métodos que buscan automatizar varias partes (o todas) del flujo de trabajo del aprendizaje automático. Las tareas que normalmente se automatizan con estas herramientas son las siguientes:
- Preprocesamiento de los datos: limpieza de los datos y transformación a un formato válido.
- Selección de variables: eliminación de variables redundantes e irrelevantes.
- Elección del modelo y optimización de hiperparámetros: elección del mejor modelo y sus hiperparámetros.
Como podéis imaginaros, las ventajas que nos ofrecen estas herramientas son innumerables y nos permiten:
- Ahorrar una gran cantidad de tiempo
- Aumentar la productividad al simplificar el proceso
- En algunos casos, conseguir mejores modelos, al reducir la posibilidad de errores que puedan ocurrir en las tareas manuales.
- También consiguen democratizar el desarrollo de los modelos de Machine Learning y permiten que usuarios con poco conocimiento en la materia puedan construir sus propios modelos.
Sin embargo, estas herramientas no solo están dirigidas a usuarios inexpertos, ya que también permiten que los científicos de datos o expertos en el campo del Machine Learning puedan dejar de lado algunas tareas tediosas para enfocarse en otras más creativas e interesantes y mejorar de esta manera su productividad.
Sin embargo, es importante señalar que el AutoML no puede realizar todas las responsabilidades propias de un científico de datos, como, por ejemplo, la formulación del problema o la interpretación del modelo y de los resultados obtenidos.
Dicho esto, pasemos a conocer algunas de las herramientas disponibles que nos permiten automatizar el proceso de ML.
Herramientas de AutoML disponibles
Como consecuencia del acelerado crecimiento de los últimos años y la gran demanda de este tipo de técnicas, muchas compañias han creado sus propias soluciones de AutoML, entre las que encontramos Cloud AutoML de Google, Azure Machine Learning de Microsoft, Auto-sklearn, entre otras.
Normalmente, la mayoría de estas soluciones cubren solo parcialmente alguna de las fases del proceso. Por ejemplo, herramientas como Auto-sklearn, realizan una búsqueda para encontrar el mejor algoritmo de Machine Learning e hiperparámetros de manera automática.
No obstante, también encontramos otras herramientas como Google Cloud AutoML, que utilizaremos posteriormente en la parte práctica, que cubren prácticamente la totalidad del proceso de creación del modelo y, además, están basadas en la nube.
Utilizando Cloud AutoML para aplicar sentiment analysis en críticas de películas
En una anterior publicación de sentiment analyis de este blog, aprendimos los pasos para implementar un modelo de regresión logística para distinguir entre reseñas de películas positivas y negativas. En ese mismo tutorial, describimos como realizar el preprocesamiento de los datos (limpieza, tokenización, etc.), representación de los textos de manera numérica mediante la técnica tf-idf, optimización de hiperparámetros y entrenamiento del modelo y evaluación.
Gracias a la herramienta AutoML que nos ofrece Google llamada Cloud AutoML Natural Language, podemos ahorrarnos las tareas anteriormente descritas y, además, seremos capaces de entrenar un modelo de clasificación de sentimient analysis de alta calidad en cuestión de minutos y sin tener que escribir código.
Como seguramente habéis imaginado, en esta última sección práctica, explicaremos como utilizar Cloud AutoML para implementar un modelo capaz de identificar si una crítica de película tiene un sentimiento positivo o negativo.
Para ello, utilizaremos el mismo conjunto de datos del artículo de sentiment analysis, consistente en alrededor de 4.800 críticas de usuarios y sus puntuaciones correspondientes de la página web de filmaffinity (www.filmaffinity.com). De las críticas extraídas, la mitad están etiquetadas como positivas (1) y la otra mitad como negativas (0).
A continuación, puedes ver una muestra de 5 críticas con sus correspondientes clases:

Muestra de 5 textos etiquetados
Antes de empezar a construir el modelo, necesitareis crear una cuenta de Google Cloud donde se os proporcionarán 300 USD de crédito gratuito. Una vez habeis iniciado sesión con vuestra cuenta de Google Cloud Platform Console, debéis seleccionar la opción Vertex AI en el menú de navegación y hacer clic en Panel.
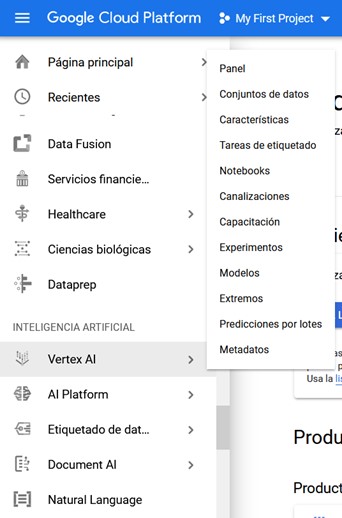
Menú de navegación de la consola de Google Cloud Platform
Una vez en el panel, deberemos habilitar la API de Vertex AI, necesaria para poder subir nuestro dataset y entrenar el modelo:

Botón para habilitar la API de Vertex AI
Para entrenar el modelo de clasificación con AutoML Natural Language, deberéis proporcionar los documentos de texto y las categorías de clasificación que se aplican a esos documentos.
Es importante que el archivo CSV que pasemos al modelo como entrada contenga en cada fila un documento de texto y su correspondiente etiqueta (crítica positiva o negativa).
Para subir nuestro conjunto de datos a Google Cloud hacemos clic en CREAR CONJUNTO DE DATOS como se muestra en la siguiente imagen:
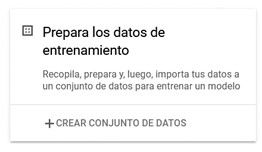
Bloque para cargar su conjunto de datos
En la siguiente pantalla sólo tenéis que seleccionar el tipo de datos que vais a cargar (Análisis de opiniones de texto) y el nombre del conjunto de datos:
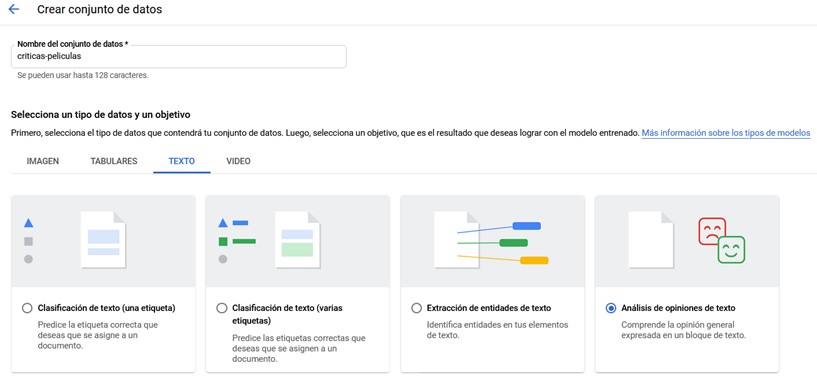
Sección para subir el conjunto de datos
En este punto, podemos establecer la puntuación máxima de la opiniones. En nuestro caso, lo dejamos a 1 ya que solo tenemos 2 categorías.
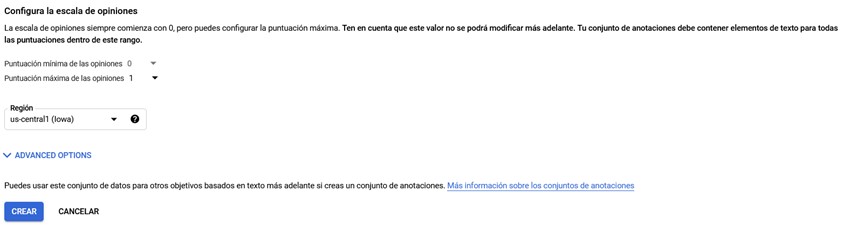
Pantalla para configurar la escala de opiniones
Una vez elegido todo, debeis pulsar en el botón CREAR.
En la siguiente pantalla, debéis elegir un método de importación. En nuestro caso elegimos la opción Sube archivos de importación desde tu computadora para seleccionar el archivo CSV con los textos previamente descargados.

Pantalla para seleccionar un método de importación
A continuación, tendréis que seleccionar una ruta de almacenamiento en la nube donde se almacenarán los datos.
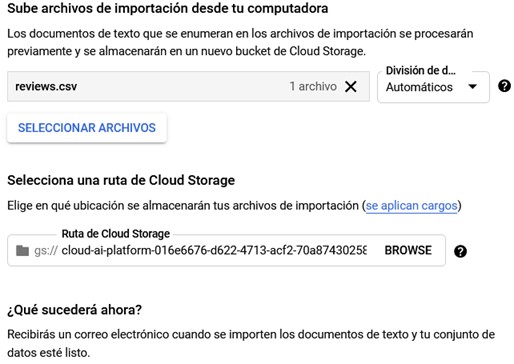
Sección para cargar sus archivos de importación desde el ordenador
La importación de datos tardará unos minutos en finalizar. Una vez importados, podréis ver los textos correctamente cargados junto con su etiqueta, como se muestra en la siguiente imagen:
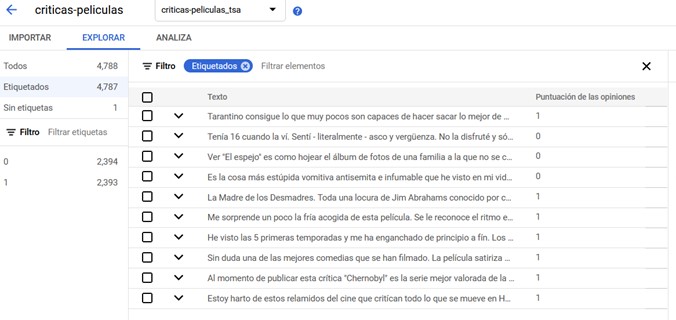
Conjunto de datos subidos a Google Cloud
El siguiente paso consiste en entrenar el modelo de clasificación. Para ello volvemos al panel principal y hacemos clic en ENTRENAR NUEVO MODELO.
Bloque para entrenar un modelo nuevo
A continuación, sólo tenéis que indicar el nombre de su modelo y luego hacer clic en CONTINUAR.

Sección para entrenar el modelo
Además, podéis asignar manualmente el porcentaje de muestras que se utilizarán como conjunto de entrenamiento, validación y test cambiando la opción de división de datos.
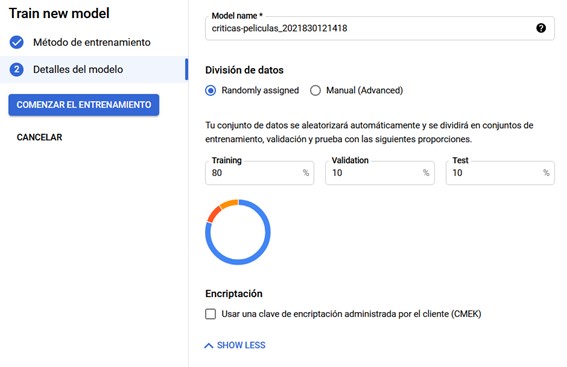
Sección para asignar el porcentaje de muestras utilizadas como conjunto de entrenamiento, validación y prueba
Ahora es el momento de entrenar el modelo. Para ello hacemos clic en INICIAR ENTRENAMIENTO para iniciar el proceso de entrenamiento del modelo.
Al cabo de unas horas, volveréis a recibir un correo electrónico, esta vez para informaros de que el modelo ha terminado su entrenamiento.
Una vez finalizado el entrenamiento, podéis volver a vuestro modelo en Google Cloud Platform y ver los resultados del entrenamiento en la pestaña EVALUAR. En primer lugar, la herramienta nos muestra un conjunto de métricas de evaluación que indican el rendimiento del modelo en el conjunto de datos de prueba.
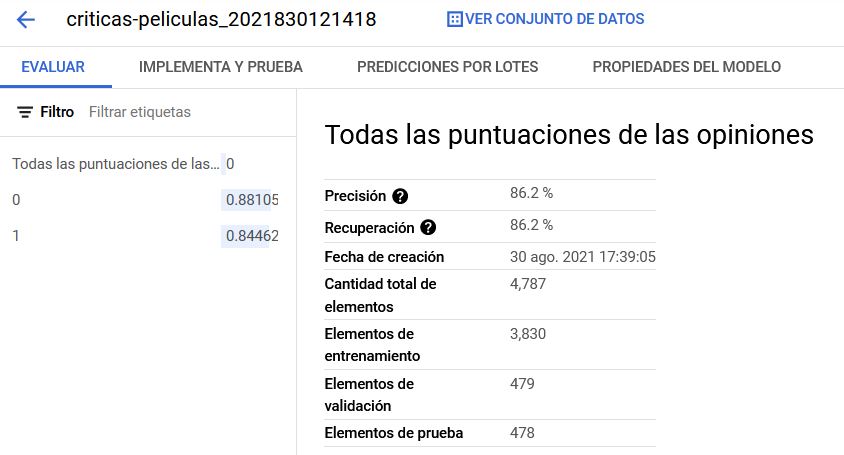
Métricas de evaluación del modelo
En este caso, podemos ver que que nuestro clasificador alcanzó una precisión media de aproximadamente 0,86. No está nada mal. Ahora pasamos a observar la matriz de confusión para ver si el clasificador funciona tan bien a la hora de cada clase.

Matriz de confusión
A simple vista, podemos decir que el rendimiento del modelo es bastante similar e incluso ligeramente superior al del modelo de regresión logística implementado en la publicación de sentiment analysis, ¡Y todo ello sin tener que escribir ni una linea de código!
Por último, para desplegar y empezar a utilizar vuestro modelo debéis seleccionar la pestaña IMPLEMENTA Y PRUEBA.
Sección para desplegar el modelo
Eso es todo por hoy. En esta publicación hemos aprendido qué es AutoML y cómo construir un modelo con Cloud AutoML de Google en un par de horas para para distinguir entre reseñas de películas positivas y negativas. Esperamos que este tutorial te haya resultado útil y que te haya inspirado a crear tus propios modelos. ¡Hasta la próxima!


















