Introducción al topic modeling con Gensim (II): asignación de tópicos
También comenzamos a realizar nuestro ejemplo práctico, en el cual estamos interesados en aplicar el modelo LDA para la asignación de tópicos en noticias periodísticas. Para ello, recopilamos 5665 noticias extraídas de distintos periódicos digitales españoles y les aplicamos el preprocesamento necesario que incluye la tokenización de los textos, la eliminación de las stopwords y el proceso de stemming. Ahora que ya tenemos todo lo necesario, ¡es hora de pasar a la acción!
En esta publicación, seguiremos justo donde lo dejamos (si te perdiste el anterior puedes echarle un vistazo aquí) y construiremos por fin nuestro modelo LDA entrenándolo con las noticias ya preprocesadas usando para ello la librería Gensim de Python. Finalmente, evaluaremos los resultados obtenidos.
Pero antes que nada, tenemos que construir un diccionario con todas las palabras y un corpus con la frecuencia de las palabras en cada documento. Así, estos dos serán las principales entradas de nuestro modelo LDA. Veamos en primer lugar cómo podemos obtenerlos.
Generación del diccionario y corpus, principales entradas del modelo LDA
Primeramente, importamos las librerías que vamos a necesitar para este tutorial práctico:
from gensim.corpora import Dictionary
from gensim.models import LdaModel
import random
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud
%matplotlib inline
La generación de estos diccionarios con la librería Gensim es tan fácil como crear un objeto de tipo Dictionary pasándole como argumento las listas de palabras. En nuestro caso y como vimos en el anterior post, tenemos almacenadas las listas de palabras, pertenecientes al conjunto de noticias, en la columna Tokens de nuestro objeto DataFrame.
diccionario = Dictionary(df.Tokens)
print(f'Número de tokens: {len(diccionario)}')
filter_extremes, que nos proporciona el objeto Dictionary y que nos servirá para mantener únicamente aquellos tokens que se encuentran en al menos 2 documentos (no_below) y los que están contenidos en no más del 80% de documentos (no_above). En este último caso le debemos pasar una fracción del tamaño del corpus como podéis ver en el siguiente ejemplo:diccionario.filter_extremes(no_below=2, no_above = 0.8)
print(f'Número de tokens: {len(diccionario)}')
Luego, inicializamos el corpus en base al diccionario que acabamos de crear. Cada documento se transformará en una bolsa de palabras (BOW del inglés bag-of-words) con las frecuencias de aparición.
Tras aplicar esta técnica veremos que cada documento está representado como una lista de tuplas donde el primer elemento es el identificador numérico de la palabra y el segundo es el número de veces que esa palabra aparece en el documento.
A continuación se muestra como construimos el corpus aplicando la función doc2bow del diccionario a cada lista de palabras:
# Creamos el corpus
corpus = [diccionario.doc2bow(noticia) for noticia in df.Tokens]
# Mostramos el BOW de una noticia
print(corpus[6])
print(corpus[6])) en la que los primeros 5 elementos son: [(3, 1), (25, 1), (26, 6), (29, 1), (40, 1) …].
Así, la primera tupla (3, 1) indica que, para el primer documento, la palabra con el identificador 3 aparece una vez. Mediante el comando (diccionario[3]) podéis ver que el identificador 3 corresponde al token afirm.
Construyendo el modelo LDA
Es hora de construir nuestro modelo LDA. Para ello simplemente creamos un objeto LdaModel de la librería Gensim pasándole como argumento el corpus y el diccionario y le indicamos adicionalmente los siguientes parámetros:
num_topics: número de tópicos. Para este tutorial extraeremos 50 tópicos.random_state: parámetro para controlar la aleatoriedad del proceso de entrenamiento y que nos devuelva siempre los mismos resultados.chunksize: número de documentos que será utilizado en cada pasada de entrenamiento.passes: número de pasadas por el corpus durante el entrenamiento.alpha: representa la densidad de tópicos por documento. Un mayor valor de este parámetro implica que los documentos estén compuestos de más tópicos. En este caso, fijamos el valor enauto.
Por supuesto, hay más parámetros para tener en cuenta en el entrenamiento de un modelo LDA y que podéis consultar en la documentación de Gensim, pero en este tutorial solo utilizaremos los anteriores descritos.
En el siguiente código mostramos como construimos nuestro modelo:
lda = LdaModel(corpus=corpus, id2word=diccionario,
num_topics=50, random_state=42,
chunksize=1000, passes=10, alpha='auto')
print_topics indicándole el número de tópicos y el número de palabras por tópico que queremos que se muestre:topicos = lda.print_topics(num_words=5, num_topics=20)
for topico in topicos:
print(topico)
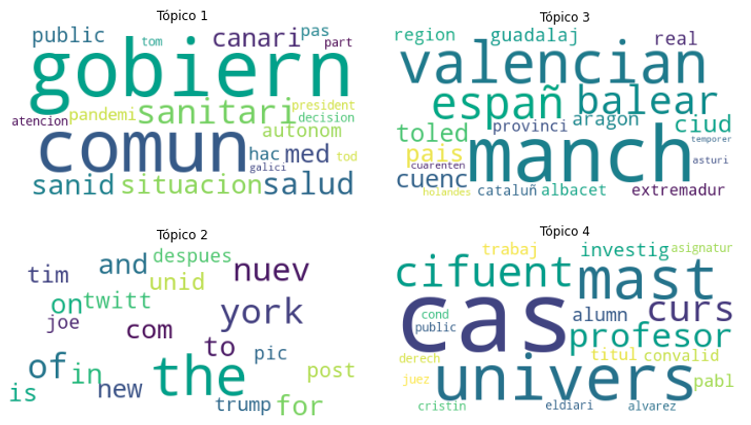
Es fácil también interpretar que el tópico 26 tiene relación con la economía al contener palabras como millón, eur y banc y el tópico 38 se centra en elecciones, ya que sus palabras más significativas son encuest, votant y dat.
También podemos visualizar las palabras más importantes de cada tópico mediante nube de palabras, donde el tamaño de cada palabra corresponde con su contribución en el tópico. En el siguiente código construimos un gráfico de nube de palabras gracias a la librería wordcloud:
for i in range(1, 5):
plt.figure()
plt.imshow(WordCloud(background_color='white', prefer_horizontal=1.0)
.fit_words(dict(lda.show_topic(i, 20))))
plt.axis("off")
plt.title("Tópico " + str(i))
plt.show()
Evaluación del modelo
Para evaluar el rendimiento del modelo, estimaremos los tópicos en dos documentos diferentes. En el primer caso, escogeremos un documento de entre las noticias utilizadas en el corpus para entrenar el modelo y para la segunda prueba utilizaremos una nueva noticia.
Así, empezamos escogiendo una noticia del corpus al azar y mostramos su contenido y titular:
indice_noticia = random.randint(0,len(df))
noticia = df.iloc[indice_noticia]
print("Titular: " + noticia.Titular)
print(noticia.Noticia)
Primero debemos obtener la representación BOW del documento y la distribución de los tópicos:
bow_noticia = corpus[indice_noticia]
distribucion_noticia = lda[bow_noticia]
# Indices de los topicos mas significativos
dist_indices = [topico[0] for topico in lda[bow_noticia]]
# Contribución de los topicos mas significativos
dist_contrib = [topico[1] for topico in lda[bow_noticia]]
distribucion_topicos = pd.DataFrame({'Topico':dist_indices,
'Contribucion':dist_contrib })
distribucion_topicos.sort_values('Contribucion',
ascending=False, inplace=True)
ax = distribucion_topicos.plot.bar(y='Contribucion',x='Topico',
rot=0, color="orange",
title = 'Tópicos mas importantes'
'de noticia ' + str(indice_noticia))
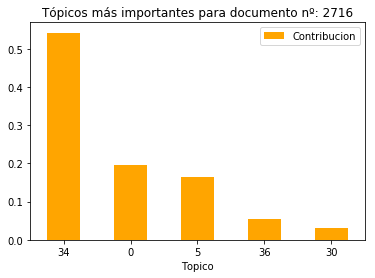
El tópico más predominante en la noticia es el 34, seguido de los tópicos 0 y 5. Seguidamente, imprimimos las palabras más significativas de estos.
for ind, topico in distribucion_topicos.iterrows():
print("*** Tópico: " + str(int(topico.Topico)) + " ***")
palabras = [palabra[0] for palabra in lda.show_topic(
topicid=int(topico.Topico))]
palabras = ', '.join(palabras)
print(palabras, "\n")
¡El modelo no pinta nada mal! Para la segunda prueba, asignaremos los tópicos a un nuevo documento no utilizado en el entrenamiento del modelo LDA. La noticia escogida trata sobre la violencia de género en Cantabria.
Antes de nada abrimos la noticia que esta en formato texto:
texto_articulo = open("noticia1.txt")
articulo_nuevo = texto_articulo.read().replace("\n", " ")
texto_articulo.close()
articulo_nuevo = limpiar_texto(articulo_nuevo)
articulo_nuevo = tokenizer.tokenize(articulo_nuevo)
articulo_nuevo = filtrar_stopword_digitos(articulo_nuevo)
articulo_nuevo = stem_palabras(articulo_nuevo)
articulo_nuevo
bow_articulo_nuevo = diccionario.doc2bow(articulo_nuevo)
# Indices de los topicos mas significativos
dist_indices = [topico[0] for topico in lda[bow_articulo_nuevo]]
# Contribucion de los topicos mas significativos
dist_contrib = [topico[1] for topico in lda[bow_articulo_nuevo]]
distribucion_topicos = pd.DataFrame({'Topico':dist_indices,
'Contribucion':dist_contrib })
distribucion_topicos.sort_values('Contribucion',
ascending=False, inplace=True)
ax = distribucion_topicos.plot.bar(y='Contribucion',x='Topico',
rot=0, color="green",
title = 'Tópicos más importantes'
'para documento nuevo')
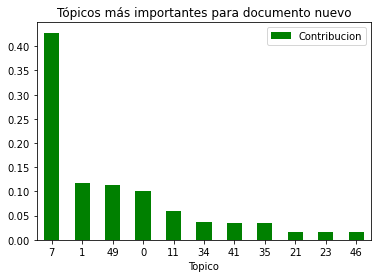
El tópico 7 es el más significante con diferencia en la noticia. Imprimimos de nuevo las palabras más significativas:
for ind, topico in distribucion_topicos.iterrows():
print("*** Tópico: " + str(int(topico.Topico)) + " ***")
palabras = [palabra[0] for palabra in lda.show_topic(
topicid=int(topico.Topico))]
palabras = ', '.join(palabras)
print(palabras, "\n")
Finalmente guardamos el modelo y el diccionario para utilizarlo más adelante. Para ello usamos la función save() en ambos casos:
lda.save("articulos.model")
diccionario.save("articulos.dictionary")
Eso ha sido todo por hoy. En este tutorial hemos visto que el modelo LDA es una buena herramienta para clasificar noticias periodísticas, pero convendría utilizar muchas más noticias para entrenar el modelo y de esta forma obtener un mejor rendimiento.
En la siguiente publicación de la serie aprenderemos como calcular la similitud de documentos a partir de los tópicos obtenidos. Mientras tanto, el cuaderno Jupyter con el código utilizado hasta ahora lo podéis descargar aquí. ¡Hasta la próxima!
También te puede interesar:
¡Síguenos en las redes!
![]()
![]()
Destacados












Newsletter

Últimos posts

Aprendizaje por Refuerzo: Fundamentos y aplicaciones

Conociendo a tu Audiencia: Análisis de Segmentación de Clientes

Slick: La mejor forma de interactuar con bases de datos en Scala
Cómo trabajar con Futures en Scala para programación asíncrona

Cómo Construir un Modelo de Detección de Fraude con Python

Cómo Construir una API de Machine Learning con Flask

Cómo Prepararte para una Entrevista de Ingeniero de Datos en AWS

Gemini vs Bard: Comparativa de capacidades y uso de prompts
Buenas tardes. Agradecida por la explicación. Ahora, quisiera saber si después de realizar estas actividades, se puede utilizar Word2vec para investigar sobre la similitud de los textos. Este ejercicio me es útil por una investigación que debo realizar aunque en la misma parto de una frase para buscar el contexto.
Buenos días Ro. Sí, es posible utilizar Word2vec u otras técnicas de word embeddings para la similitud de textos y tenía pensado investigarlos y publicar algún artículo sobre ello más adelante. Saludos!