Blog
El mundo de los datos
Artículos en español sobre Machine Learning, Deep Learning, estadística, Python, NPL y otros de los campos que componen el apasionante mundo de los datos.


Extracción de datos de sitios web con Scrapy (II): rastreando todas las URLs del sitio web de Zara
En este post construimos un rastreador con Scrapy que extrae los datos de manera recursiva todas las URLs del sitio web de Zara.

Extracción de datos de sitios web con Scrapy (I): recopilando información de productos de Zara
En este tutorial explicamos como extraer con Scrapy los datos de la web de Zara de forma automatizada para finalmente almacenarlos en MongoDB.

Dominando Apache Spark (IX): Explorando Delta Lake
Exploramos cómo Delta, una evolución de Parquet, mejora el procesamiento de datos en Apache Spark. Delta agrega transacciones ACID, control de versiones, actualizaciones y esquema evolutivo, mejorando la integridad, eficiencia y flexibilidad de los datos.

Dominando Apache Spark (VIII): El formato Parquet
Descubre cómo el formato Parquet en Apache Spark revoluciona la eficiencia del procesamiento de datos. Comprende sus ventajas, diferencias con otros formatos y aprende a utilizarlo con ejemplos prácticos.

Dominando Apache Spark (VII): Funciones para cargar y exportar datos en PySpark
En este artículo, exploramos funciones avanzadas para importar y exportar datos en PySpark.

Dominando Apache Spark (VI): Diferentes tipos de Joins en DataFrames con ejemplos en PySpark
Descubre los secretos de los joins en DataFrames con Spark en este artículo. Aprende a utilizar diferentes tipos de joins en PySpark con ejemplos detallados para perfeccionar tus habilidades de procesamiento de datos.

Dominando Apache Spark (V): Explorando los Datasets
En este tercer artículo de la serie «Dominando Apache Spark», exploramos las estructuras de datos clave: RDD, DataFrames y Datasets. Comparamos sus características y usos, brindando una visión completa de cómo trabajar con datos en Spark. Próximamente, nos enfocaremos en operaciones y transformaciones.
Dominando Apache Spark (IV): Explorando los DataFrames
Descubre los fundamentos de DataFrames en Apache Spark, desde su creación y características hasta ejemplos de transformaciones y acciones.
Dominando Apache Spark (III): Explorando RDD (Resilient Distributed Datasets) y su poder en el procesamiento de datos
En este artículo exploramos RDD, una estructura fundamental para el procesamiento de datos distribuidos. Descubre cómo RDDs permiten la manipulación y transformación de datos a gran escala.
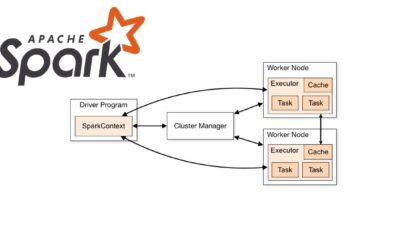
Dominando Apache Spark (II): Funcionamiento interno y arquitectura
En este artículo profundizamos en la arquitectura y el funcionamiento interno de Spark, destacando componentes clave.
Dominando Apache Spark (I): Introducción y ventajas en el procesamiento de grandes volúmenes de datos
En el artículo, exploramos la historia y ventajas de Apache Spark como un marco de procesamiento de datos de código abierto. Destacamos su evolución y las razones para su popularidad en el procesamiento de datos a gran escala, incluyendo su velocidad y capacidad de procesamiento en memoria.
Extracción de datos de Twitter con Python (sin consumir la API)
En esta publicación os enseñaremos como poder extraer datos de Twitter en Python mediante la librería Twint. De esta forma, podremos obtener facilmente los últimos tweets que contengan cierta palabra o que pertenezcan a un determinado usuario y aplicar varios filtros.

Introducción al topic modeling con Gensim (III): similitud de textos
En este post mostramos como utilizar la técnica de topic modeling para obtener la similitud entre textos teniendo en cuenta la semántica

Introducción al topic modeling con Gensim (II): asignación de tópicos
En esta publicación aprenderás como entrenar un modelo LDA con noticias periodísticas para la asignación de tópicos, usando para ello la librería Gensim de Python.

Introducción al topic modeling con Gensim (I): fundamentos y preprocesamiento de textos
En esta publicación entenderéis los fundamentos del topic modeling (modelo LDA) y se mostrará como realizar el preprocesamento necesario a los textos: tokenización, eliminación de stopwords, etc.
Otros 5 trucos de Jupyter Notebook que probablemente desconozcas
En este artículo se explican 5 nuevos trucos para Jupyter Notebook que probablemente desconozcas y que mejorarán vuestra productividad.
5 trucos para Jupyter Notebook que no debes perderte
Descubre 5 trucos para Jupyter Notebook no tan conocidos que te ayudarán familiarizarte más con esta herramienta y ser más eficiente.

Aprendizaje por Refuerzo: Fundamentos y aplicaciones
Descubre los fundamentos del Aprendizaje por Refuerzo, sus elementos clave, ejemplos prácticos con OpenAI Gym y casos de uso en la industria.

Conociendo a tu Audiencia: Análisis de Segmentación de Clientes
Descubre cómo el análisis de segmentación de clientes puede transformar tu negocio. Aprende métodos, aplicaciones y beneficios clave para conectar con tu audiencia.

Slick: La mejor forma de interactuar con bases de datos en Scala
Descubre Slick, la biblioteca para interactuar con bases de datos en Scala. Aprende a configurarlo, realizar consultas y optimizar tus operaciones. ¡Domina la persistencia de datos!
Cómo trabajar con Futures en Scala para programación asíncrona
Aprende a usar Futures en Scala para programación asíncrona. Descubre cómo manejar la concurrencia, evitar errores comunes y compararlo con Async/Await.

Cómo Construir un Modelo de Detección de Fraude con Python
Aprende a construir un modelo de detección de fraude con Python. Descubre técnicas de ingeniería de características y algoritmos de clasificación para proteger tu negocio.

Cómo Construir una API de Machine Learning con Flask
Aprende a construir una API de Machine Learning con Flask. Integra tus modelos y ofrece predicciones en tiempo real. Guía paso a paso y ejemplos prácticos.
Cómo Prepararte para una Entrevista de Ingeniero de Datos en AWS
Prepárate para tu entrevista de Ingeniero de Datos en AWS. Aprende sobre servicios clave como Redshift, S3, EMR y las arquitecturas de Data Lake.

Gemini vs Bard: Comparativa de capacidades y uso de prompts
Comparativa detallada de Gemini y Bard: capacidades de procesamiento de lenguaje, integración con herramientas y experiencia del usuario. Descubre cuál se adapta mejor a ti.

Estadística Computacional: Algoritmos para el Análisis de Datos
Descubre los algoritmos clave de la estadística computacional: Monte Carlo, Bootstrap/Jackknife y EM. Aprende cómo aplicarlos al análisis de datos complejo y a la extracción de conocimiento.
Gracias por visitar
El Mundo De Los Datos
Si tienes cualquier duda, sugerencia o crítica puedes escribirme.