Dominando Apache Spark (II): Funcionamiento interno y arquitectura
En el primer artículo de nuestra colección «Dominando Apache Spark», exploramos la historia y las ventajas técnicas de Apache Spark. En este segundo artículo, profundizaremos en los componentes, funcionamiento interno y la arquitectura de Spark. Comprender cómo Spark maneja el procesamiento de datos a gran escala es esencial. ¡Empecemos con ello!
Arquitectura y funcionamiento de Spark
El funcionamiento de Spark se basa en una arquitectura distribuida que involucra varios componentes clave:
- Programa Controlador (Driver Program): El programa controlador es el núcleo de una aplicación Spark. Este programa inicia la ejecución y coordina las tareas en el clúster. Funciona como el cerebro de la aplicación y contiene la lógica principal. Se comunica con el administrador de clúster para asignar recursos y coordinar la ejecución.
- Administrador de Clúster (Cluster Manager): El administrador de clúster es responsable de asignar recursos en el clúster para las aplicaciones. Puede ser de varios tipos, incluyendo el administrador de clúster independiente de Spark, Mesos, YARN o Kubernetes. Posteriormente veremos cada uno de ellos. Estos administradores distribuyen recursos entre las aplicaciones y garantizan un uso eficiente de los nodos del clúster.
- Ejecutores (Executors): Los ejecutores son procesos que se ejecutan en los nodos del clúster. Estos procesos realizan la ejecución real de las tareas de procesamiento de datos y almacenan datos temporales para la aplicación. Cada aplicación Spark obtiene sus propios ejecutores que trabajan en paralelo en múltiples hilos.
- Trabajadores (Workers): Estos son las instancias en las cuales los ejecutores se alojan para llevar a cabo la ejecución del código de la aplicación que ha sido escrita por el usuario en el clúster.
Las aplicaciones de Spark se ejecutan como conjuntos independientes de procesos en un clúster, coordinados por el objeto SparkContext en su programa principal (llamado programa controlador).
Así, para ejecutarse en un clúster, SparkContext puede conectarse a varios tipos de administradores de clúster que asignan recursos entre las aplicaciones. Una vez conectado, Spark adquiere ejecutores en nodos del clúster, que son los procesos que ejecutan los cálculos y almacenan datos temporales para su aplicación.
A continuación, envía el código de su aplicación (definido por archivos JAR o Python pasados a SparkContext) a los ejecutores. Finalmente, SparkContext envía tareas a los ejecutores para su ejecución.
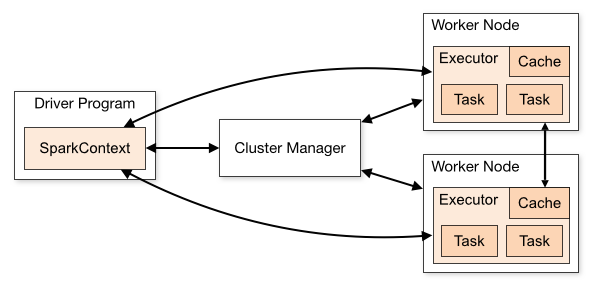
Hay varias cosas útiles que destacar sobre esta arquitectura:
- Como vemos, Spark implementa una arquitectura de tipo maestro/esclavo y además trabajade manera distribuida. Sin embargo, para lograr una ingesta de datos distribuida, el archivo debe estar almacenado en un sistema de archivos distribuido como HDFS (Hadoop Distributed File System), o en servicios en la nube como S3, entre otros.
- Cada aplicación obtiene sus propios procesos de ejecutores, que permanecen activos durante toda la duración de la aplicación y ejecutan tareas en múltiples hilos. Esto tiene la ventaja de aislar las aplicaciones entre sí, tanto en el lado de la programación (cada controlador programa sus propias tareas) como en el lado del ejecutor (las tareas de diferentes aplicaciones se ejecutan en diferentes JVM). Sin embargo, también significa que los datos no se pueden compartir entre diferentes aplicaciones de Spark (instancias de SparkContext) sin escribirlos en un sistema de almacenamiento externo.
- Spark es agnóstico con respecto al administrador de clúster.
- El programa controlador debe escuchar y aceptar conexiones entrantes de sus ejecutores a lo largo de su vida útil. Como tal, el programa controlador debe ser accesible en la red desde los nodos trabajadores.
- Debido a que el programa controlador programa tareas en el clúster, debe ejecutarse cerca de los nodos trabajadores, preferiblemente en la misma red de área local. Si desea enviar solicitudes al clúster de forma remota, es mejor abrir una llamada de procedimiento remoto (RPC) al controlador y hacer que envíe operaciones desde cerca que ejecutar un controlador lejos de los nodos trabajadores.
Tipos de Administradores de Clúster
El sistema actualmente admite varios administradores de clúster:
- Standalone: Un administrador de clúster sencillo incluido con Spark que facilita la configuración de un clúster.
- Apache Mesos: Un administrador de clúster general que también puede ejecutar Hadoop MapReduce y aplicaciones de servicio. Este tipo esta obsoleto.
- Hadoop YARN: El administrador de recursos en Hadoop 3.
- Kubernetes: Un sistema de código abierto para la automatización de implementación, escalado y gestión de aplicaciones en contenedores.
Componentes de Apache Spark
A continuación, se muestran los 6 componentes del Ecosistema de Apache Spark: Spark Core, Spark SQL, Spark Streaming, Spark MLlib, Spark GraphX y SparkR.
Ahora, profundicemos en los detalles de estos componentes del Ecosistema de Apache Spark.
- Spark Core: Constituye el núcleo fundamental del framework y sirve como la base sobre la cual se sustentan los demás módulos del sistema.
- Spark Streaming: Esta librería permite el procesamiento en tiempo real de datos de flujo. Con Spark Streaming, puedes gestionar flujos continuos de datos y aplicar análisis en tiempo real, lo que es esencial para aplicaciones como la detección de fraudes, el monitoreo en tiempo real y más.
- Spark SQL: Spark SQL proporciona un entorno para consultar y analizar datos estructurados utilizando SQL. Esto facilita la realización de consultas y operaciones de análisis en datos tabulares, lo que resulta útil en casos como la generación de informes y análisis de datos empresariales.
- Spark MLlib: MLlib es la biblioteca de aprendizaje automático de Spark. Ofrece una amplia variedad de algoritmos y herramientas para desarrollar modelos de machine learning, lo que lo convierte en un recurso valioso para aplicaciones de inteligencia artificial, clasificación, regresión y más.
- Spark GraphX: Esta librería se utiliza para el análisis de gráficos y datos de redes. Con GraphX, puedes realizar cálculos en grafos y graficar relaciones, lo que es útil en escenarios como redes sociales, análisis de conexiones y detección de comunidades.
- SparkR: Esta es una interfaz para Spark diseñada específicamente para R, un lenguaje de programación ampliamente utilizado en estadísticas y análisis de datos. Con SparkR, los usuarios de R pueden aprovechar la potencia de Spark para procesar y analizar datos a gran escala.
En resumen, este artículo nos ha sumergido en el mundo de Apache Spark, desglosando su arquitectura, funcionamiento interno y librerías disponibles. En el próximo artículo de esta colección, exploraremos en detalle los diferentes tipos de estructuras de datos que Spark ofrece, como RDDs, DataFrames y Datasets.
A continuación tenéis todas las publicaciones de esta serie hasta ahora:




















