Introducción al topic modeling con Gensim (III): similitud de textos
Introducción a la similitud entre textos
Existen un sinfín de técnicas para obtener la similitud entre textos y tienen muchas aplicaciones interesantes que pueden facilitarnos la vida. Por ejemplo, puede usarse para elegir los resultados en un motor de búsqueda o como sistema de recomendación que proporciona al usuario contenido que sea de su interés a partir de otros contenidos que le han gustado previamente. Este contenido puede tratarse de libros, artículos, noticias, etc.
Las técnicas más básicas para calcular la similitud entre textos solo tienen en cuenta la similitud léxica, esto es la semejanza en las palabras contenidas en los textos comparados.
Una de estas técnicas consiste en representar los textos como bolsas de palabras (BOW) y aplicar la similitud de coseno para comparar la similitud entre dos documentos. En este caso, la semejanza entre los dos textos dependerá del número de palabras que compartan.
Hay varios problemas evidentes con este tipo de técnicas. Por ejemplo, una palabra puede tener varios significados completamente diferentes y, al carecer de contexto estos métodos, no pueden saber a que significado se refiere. Además, es posible que dos frases que no compartan ninguna palabra tengan un significado muy similar, como, por ejemplo: “Fui en coche a su casa y compramos algo para comer” y “El otro día conduje hacia su piso y pedimos unas hamburguesas». Mirando solamente las palabras de las frases anteriores, concluiríamos que esas frases no tienen nada que ver. Sin embargo, las dos frases tienen un alto grado de similitud y el modelo que utilizamos debería ser capaz de detectarlo.
Por ello, es importante que los modelos tengan también en cuenta la similitud semántica, es decir, que puedan entender el significado real de las palabras o de la frase en cada contexto. Existen varios métodos para extraer esta similitud semántica de los textos, como los ampliamente utilizados modelos de word embeddings que permiten representar cada palabra como un vector de números reales y capturar de esta forma su información semántica.
Sin embargo, en esta tercera publicación sobre el topic modeling se enseñará como calcular la similitud de textos aplicando la métrica de distancia de Jensen-Shannon a las distribuciones de los tópicos del modelo LDA, que aprendimos a calcular en la anterior publicación. De esta forma, estaremos teniendo en cuenta las estructuras semánticas de los documentos extraídas mediante el modelo LDA.
En caso de que no recordéis como asignar estos tópicos a un conjunto de documentos, recomendamos que os paséis por las anteriores entregas de la serie donde aprendimos como aplicar el preprocesamento necesario (tokenización de los textos, eliminación de stopwords…) a los textos y como entrenar el modelo LDA con estos.
En el caso práctico que encontrareis en esta publicación seguiremos utilizando el mismo corpus que consiste en 5665 noticias extraídas de distintos periódicos digitales españoles y que podéis descargar aquí. Realizaremos dos pruebas distintas. En primer lugar, calcularemos las noticas más similares a otra noticia nueva sobre violencia de género. En la segunda prueba vamos a obtener las más similiares a una noticas sobre el ex presidente Trump.
Usando la métrica Jensen Shannon para calcular la distancia entre textos
El procedimiento a seguir es sencillo. Primero obtenemos la distribución de tópicos del texto nuevo del cual queremos obtener los textos más similares. Después, solo nos queda calcular la distancia entre ese texto nuevo y el resto comparando sus distribuciones de tópicos.
Para calcular la distancia entre dos distribuciones utilizaremos la métrica de distancia de Jensen-Shannon, una medida de distancia estadística entre distribuciones de probabilidad. Esta métrica nos devolverá un valor comprendido entre 0 y 1, donde cuanto menor sea este valor significa una mayor similitud entre las dos distribuciones.
La distancia de Jensen-Shannon se calcula mediante la raíz cuadrada de la divergencia de Jensen-Shannon, métrica basada en la divergencia de Kullback-Leiber. La diferencia entre ambas es que Jensen-Shannon es simétrica y siempre tiene un valor finito. Su fórmula es la siguiente:
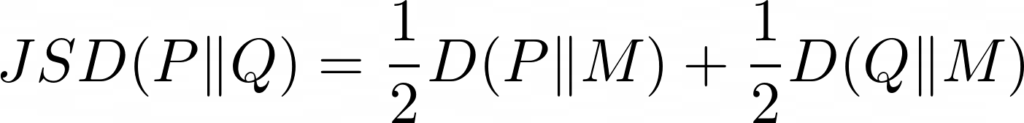
Donde P y Q son las dos distribuciones a comparar, M = (P+Q)/2 y D(P || M) es la divergencia de Kullback-Leiber entre Q y M.
En este artículo no entraremos en más detalles sobre esta métrica.
Una vez ya sabemos lo que tenemos que hacer, pongámonos manos a la obra.
Noticas más similares a una noticia sobre violencia de género
En este caso práctico, utilizamos como corpus las 5665 noticias mencionadas previamente. Como siempre, empezamos importando las librerías que vamos a necesitar:
from gensim.matutils import jensen_shannon
Después, le aplicamos el modelo LDA a una nueva noticia para obtener su distribución de tópicos con las proporciones de pertenencia de cada tópico en el documento.
Usamos la misma notica sobre violencia de género en Cantabria que ya usamos en la anterior publicación (noticia1.txt). Para la obtención de los tópicos debemos realizar el preprocesamiento al texto de la noticia y obtener su representación BOW. En el siguiente código podeís ver como abrimos la noticia en Python y realizamos las anterior dos operaciones:
texto_articulo = open("noticia1.txt")
articulo_nuevo = texto_articulo.read().replace("\\n", " ")
texto_articulo.close()
articulo_nuevo = limpiar_texto(articulo_nuevo)
articulo_nuevo = tokenizer.tokenize(articulo_nuevo)
articulo_nuevo = filtrar_stopword_digitos(articulo_nuevo)
articulo_nuevo = stem_palabras(articulo_nuevo)
bow_articulo_nuevo = diccionario.doc2bow(articulo_nuevo)
Con el método get_document_topics de Gensim obtenemos la distribución de tópicos y ajustando el parámetro minimum_probability a 0 nos aseguraremos de que ningún tópico sea descartado.
distribucion_noticia = lda.get_document_topics(bow_articulo_nuevo,
minimum_probability=0)
Esa será la distribución que necesitamos para comparar las noticias. Seguidamente creamos un método que se encarga de calcular la distancia entre dos distribuciones. De nuevo gensim nos facilitará el trabajo al contar con la función jensen_shannon que hará este cálculo por nosotros.
def calcular_jensen_shannon_sim_doc_doc(doc_dist1, doc_dist2):
"""Calcula la distancia Jensen Shannon entre dos documentos.
"""
return jensen_shannon(doc_dist1, doc_dist2)
También implementamos un método que se encarga de calcular las distancias entre las distribuciones de tópicos de nuestra noticia con las del resto y mostrar el titular de aquellas más similares, es decir, las que tengan la distancia más baja, junto con el valor de esta.
def mostrar_n_mas_similares(distribucion_noticia, n):
"""Muestra las n noticias mas similares a partir
de una distribucion de tópicos.
"""
distancias = [calcular_jensen_shannon_sim_doc_doc(
distribucion_noticia, lda[noticia]) for noticia in corpus]
mas_similares = np.argsort(distancias)
for i in range(0,n):
titular = df.iloc[int(mas_similares[i])].Titular
print(f'{i + 1}: {titular} ({distancias[mas_similares[i]]})')
Ahora simplemente usamos el método implementado pasándole como entrada la distribución de nuestra noticia y el número de noticias más similares que queremos mostrar.
mostrar_n_mas_similares(distribucion_noticia, 10)
Como podemos ver, las 10 noticias más similares calculadas mediante la distancia Jensen-Shannon son, en efecto, bastante similares a nuestra noticia. Esto lo podemos ver fácilmente observando los titulares de las noticias, que tienen que ver sobre la violencia de género en su gran mayoría.
Noticas más similares a una noticia sobre Trump
A continuación, realizamos una segunda prueba y esta vez usamos para evaluar el modelo una noticia del ex presidente Trump y las elecciones de 2020 en Estados Unidos. Empezamos, como siempre, cargando la noticia que se encuentra en formato texto (noticia2.txt).
texto_articulo = open("noticia2.txt")
articulo_nuevo = texto_articulo.read().replace("\\n", " ")
texto_articulo.close()
articulo_nuevo
Realizamos el preprocesamiento del texto y obtenemos la distribución de tópicos:
articulo_nuevo = limpiar_texto(articulo_nuevo)
articulo_nuevo = tokenizer.tokenize(articulo_nuevo)
articulo_nuevo = filtrar_stopword_digitos(articulo_nuevo)
articulo_nuevo = stem_palabras(articulo_nuevo)
articulo_nuevo
bow_articulo_nuevo = diccionario.doc2bow(articulo_nuevo)
distribucion_noticia = lda.get_document_topics(bow_articulo_nuevo,
minimum_probability=0)
Ya solo nos queda mostrar las 10 noticias más similares a la nuestra:
mostrar_n_mas_similares(distribucion_noticia, 10)
¡De nuevo vemos un buen resultado de nuestro modelo! Todas las noticias obtenidas son de Trump y la gran mayoría sobre las elecciones en Estados Unidos.
Con este post, hemos aprendido a utilizar la técnica de topic modeling para obtener la similitud entre textos teniendo en cuenta la semántica. Si queréis repasar todas las publicaciones sobre topic modeling, no dudes en echar un vistazo a nuestra serie completa:
- Introducción al topic modeling con Gensim (I): fundamentos y preprocesamiento de textos
- Introducción al topic modeling con Gensim (II): asignación de tópicos
- Introducción al topic modeling con Gensim (III): similitud de textos
Esperamos que este tutorial os haya resultado interesante y recordad que el notebook con el código utilizado hasta ahora lo podéis descargar aquí.


















