Extracción de datos de sitios web con Scrapy (I): recopilando información de productos de Zara
Introducción al web scraping
En internet tenemos a nuestra disposición grandes cantidades de datos útiles para analizar o utilizar en nuestros modelos de machine learning.
Actualmente, podemos obtener esta valiosa información gracias al web scraping, que es el nombre que recibe el proceso que nos permite extraer el contenido de sitios web de manera automática.
Así, entre otras aplicaciones del web scraping está la recopilación de las características (precio, foto, opiniones, etc.) de los productos de una tienda online o la extracción del titular y cuerpo de las noticias contenidas en un periódico digital.
Afortunadamente, en el lenguaje Python existe una gran cantidad de herramientas para rastrear y extraer datos online y en este tutorial nos centraremos en el popular framework Scrapy.
Por supuesto, también tenéis la posibilidad de implementar vuestro propio rastreador web en Python para adaptarlo a las necesidades concretas que tengáis y conocer como funciona el web scraping por dentro.
Sin embargo, mediante Scrapy tenemos una solución más rápida de utilizar y que además nos proporciona soluciones a los problemas típicos que nos encontramos a la hora de rastrear como la gestión de cookies y sesiones, el filtrado de peticiones duplicadas y el seguimiento de las redirecciones.
En este tutorial, vamos a realizar un caso práctico donde mostraremos paso a paso como extraer con Scrapy los datos de un conjunto de productos de ropa de la web de Zara de forma automatizada para finalmente almacenarlos en un sistema de almacenamiento MongoDB.
Pero primero de todo, empecemos entendiendo el funcionamiento de Scrapy.
¿Qué es Scrapy y cómo funciona?
Scrapy no es una librería como pudiera parecer, sino un completo framework de web scraping para Python. En la siguiente imagen se muestra la arquitectura de Scrapy con todos sus componentes.
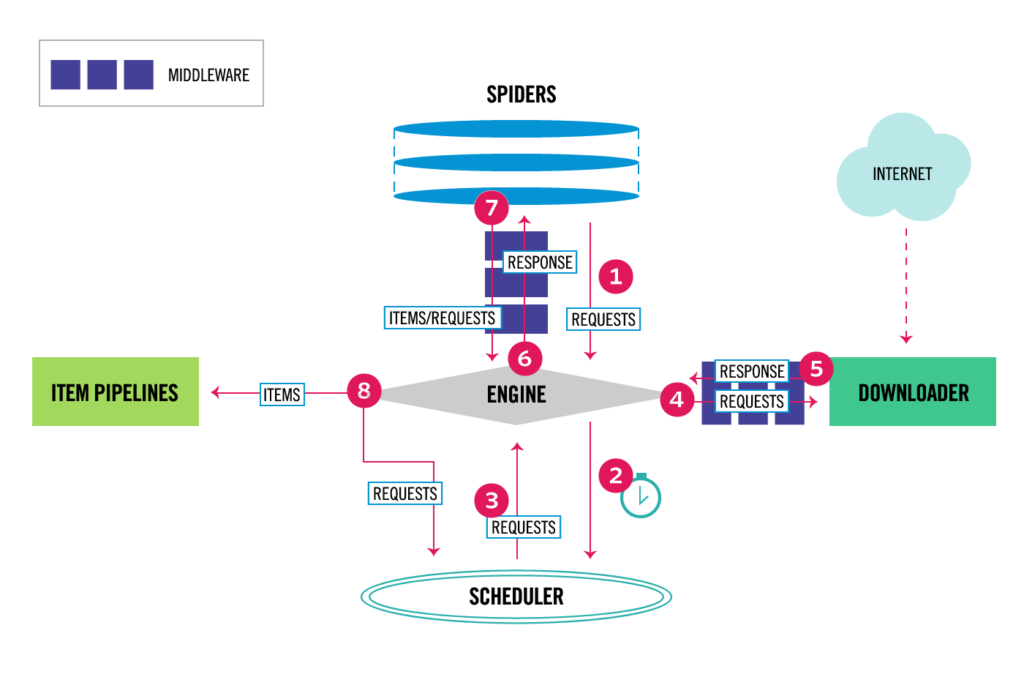
Arquitectura de Scrapy, imagen extraida de la documentación oficial
A grandes rasgos, el funcionamiento de Scrapy es el siguiente:
- En primer lugar, el Engine recibe las peticiones (Requests) iniciales que le envía la araña (Spider), las programa en el scheduler y solicita las siguientes peticiones a rastrear.
- El Scheduler va enviando las peticiones a procesar al Engine y este a su vez las envía al componente Downloader.
- La página es descargada y se crea una respuesta (Response) de esta página que el Engine se encarga de enviar a la araña para que sea procesada.
- Es entonces cuando la araña o rastreador devuelve al Engine los ítems (Items) con la información extraída de la página.
- Después, estos ítems son enviados a los Pipelines para procesar y almacenar la información.
- El proceso se repite hasta que el Scheduler se quede sin peticiones.
Una de las principales ventajas de este framework es que las peticiones se procesan y programan de manera asíncrona. Debido a ello, Scrapy no espera a que termine una petición para enviar otra y se pueden ejecutar a la vez de forma concurrente, acelerando el proceso en gran medida. Además, si una petición falla, el resto de las peticiones seguirán ejecutándose.
Una vez repasado el funcionamiento de Scrapy, es hora de pasar a la práctica.
Creación del proyecto
En este ejemplo práctico, vamos a extraer la información de una serie de productos de ropa de la tienda online de Zara. En concreto nos vamos a centrar en obtener el nombre, el precio y la descripción de cada artículo seleccionado, pero podríamos extraer cualquier elemento que queramos, incluso las imágenes.
A modo de ejemplo y para hacernos una idea, podemos ver una imagen de la página de un producto donde están señalados los tres elementos que queremos extraer con Scrapy.

Producto en Zara
Antes de nada, debemos instalar la librería Scrapy y sus dependencias mediante el siguiente comando:
pip install Scrapy
Una vez instalado, comenzamos creando un nuevo proyecto Scrapy posicionándonos en el directorio deseado y ejecutando el comando:
scrapy startproject zara
Así, se creará el directorio zara con la siguiente estructura:
zara /
scrapy.cfg # fichero de configuración
zara / # módulo del proyecto
__init__.py
items.py # fichero con la definición de los items
middlewares.py # project middlewares file
pipelines.py # fichero con los pipelines
settings.py # fichero con los ajustes del proyecto
spiders/ # directorio con nuestras arañas
__init__.py
Seguidamente definimos cada uno de estos ficheros creados en el directorio zara:
scrapy.cfg: fichero de configuración que se encuentra en el directorio raíz del proyecto y contiene el nombre del módulo con los ajustes del proyecto.zara: módulo del proyectozara/items.py: contiene las definiciones de nuestros ítems, que son los objetos estructurados que usaremos para cargar los datos que extraigamos y son muy similares a los diccionarios en Python. Así, este tipo de objeto también almacena la información mediante pares clave-valor.zara/middelwares.py: contiene los middlewares del proyecto.zara/pipelines.py: en este fichero implementaremos los pipelines que se encargarán de procesar los ítems una vez hayan sido rastreados por nuestra araña.zara/settings.py: fichero con los ajustes del proyecto.zara/spiders: directorio donde se encontrarán nuestras arañas.
Los tres grandes pasos que debemos de realizar para poder rastrear y extraer la información de nuestra página y que explicaremos a continuación son los siguientes:
- Definir nuestro objeto
Itemy los campos que queremos extraer en el ficheroitems.py. - Crear nuestra araña que extraerá la información de las páginas.
- Implementar el pipeline para procesar el ítem una vez rastreado y almacenarlo en nuestra base de datos MongoDB.
Definición del Item
Empezamos definiendo un nuevo Item al que llamaremos Producto en nuestro fichero items.py. Además, declaramos como objetos scrapy.Field los tres campos que deseamos extraer de cada artículo: su nombre, descripción y precio.
import scrapy class Producto(scrapy.Item): nombre = scrapy.Field() precio = scrapy.Field() descripcion = scrapy.Field()
Creación de nuestra araña y extracción de los datos
Las arañas o rastreadores son clases que se encargan de extraer la información de cada página. En este caso, creamos un nuevo fichero en la carpeta spiders llamado zara_spider.py. Antes de mostrar el código completo de nuestra clase a la que llamaremosZaraSpider, es importante explicar la función de ciertos atributos y métodos que debemos definir.
name: nombre de nuestra araña.
name = "zara"
start_urls: cuando se ejecuta un proceso de Scrapy, la araña comienza a hacer peticiones a las URLs que se han definido en el atributostart_urls. En nuestro caso utilizamos una lista con la URL de los siete productos de ropa de Zara de los cúales queremos obtener los datos:
# URLs para comenzar a rastrear
start_urls = [
'https://www.zara.com/es/es/abrigo-oversize-con-lana-p02268744.html?v1=99425057&v2=1712675',
'https://www.zara.com/es/es/camiseta-b%C3%A1sica-medium-weight-p00381300.html?v1=86668649&v2=1720409',
'https://www.zara.com/es/es/sudadera-capucha-cremalleras-p00761406.html?v1=99422974&v2=1720409',
'https://www.zara.com/es/es/pantal%C3%B3n-chino-carrot-fit-p00706475.html?v1=89361432&v2=1717453',
'https://www.zara.com/es/es/sandalia-plana-track-p13647710.html?v1=86083745&v2=1471790',
'https://www.zara.com/es/es/polo-rayas-p09240419.html?v1=99423481&v2=1720387',
'https://www.zara.com/es/es/mochila-t%C3%A9cnica-p13201720.html?v1=99425027&v2=1720458'
]
Nuestra araña ya tiene un método start_requests() implementado por defecto, que se encarga de generar una respuesta por cada una de estas URLs y de enviarla al método callback por defecto denominado parse.
Asimismo, podéis sobreescribir este método si queréis modificar funcionamiento, por ejemplo, en caso de que busquéis filtrar las URLs con las que comenzar a rastrear.
allowed_domains: lista opcional con el nombre de los dominios que nuestra araña puede rastrear. En este ejemplo no pasaría nada en caso de que no la añadamos ya que nos vamos a limitar a rastrear únicamente las URLs indicadas enstart_urls.
# Dominios permitidos allowed_domains = ['zara.com']
parse: como hemos mencionado antes, el rastreador llama a este método de callback, pasándole los objetos de respuesta de las páginas como argumento. En el métodoparsenos encargaremos de extraer la información que queramos de cada URL mediante expresiones XPaths, expresiones regurales (REgex) o selectores CSS.
En nuestro caso, utilizaremos el lenguaje XPath, que trata a los documentos XML y HTML como árboles y nos permitirá seleccionar los diferentes nodos como por ejemplo, un atributo, de manera sencilla. No me detendré a explicar la sintaxis de este lenguaje, pero podéis echar un vistazo a este tutorial con el que seguramente podráis extraer la mayoría de los campos que necesitéis.
Por ejemplo, para extraer el nombre de una prenda de una página de Zara, podemos utilizar la siguiente expresión:
//h1[@class="product-detail-info__name"]/text()
Esta expresión selecciona los nodos de texto que se encuentran dentro de los elementos h1 cuya clase (class) sea igual a product-detail-info__name.
Dicho todo esto, solo nos queda juntar todas las piezas y mostrar el código completo de nuestra clase ZaraSpider.
import scrapy
from zara.items import Producto
class ZaraSpider(scrapy.Spider):
# Nombre de la araña
name = "zara"
# Dominios permitidos
allowed_domains = ['zara.com']
# URLs para comenzar a rastrear
start_urls = [
'https://www.zara.com/es/es/abrigo-oversize-con-lana-p02268744.html?v1=99425057&v2=1712675',
'https://www.zara.com/es/es/camiseta-b%C3%A1sica-medium-weight-p00381300.html?v1=86668649&v2=1720409',
'https://www.zara.com/es/es/sudadera-capucha-cremalleras-p00761406.html?v1=99422974&v2=1720409',
'https://www.zara.com/es/es/pantal%C3%B3n-chino-carrot-fit-p00706475.html?v1=89361432&v2=1717453',
'https://www.zara.com/es/es/sandalia-plana-track-p13647710.html?v1=86083745&v2=1471790',
'https://www.zara.com/es/es/polo-rayas-p09240419.html?v1=99423481&v2=1720387',
'https://www.zara.com/es/es/mochila-t%C3%A9cnica-p13201720.html?v1=99425027&v2=1720458'
]
def parse(self, response):
producto = Producto()
# Extraemos el nombre del producto, la descripcion y su precio
producto['nombre'] = response.xpath('//h1[@class="product-detail-info__name"]/text()').extract_first()
producto['precio'] = response.xpath('//span[@class="price__amount"]/text()').extract_first()
producto['descripcion'] = response.xpath('//div[@class="expandable-text product-detail-info__description"]//text()').extract_first()
yield producto
Almacenando los ítems en MongoDB
El siguiente paso consiste en implementar un pipeline que se encargue de almacenar cada página en una colección de MongoDB (Scrapy también permite exportar los datos a ficheros CSV o JSON mediante los Feed Exports).
De esta manera, para almacenar la información MongoDB añadiremos al fichero pipelines.py la implementación de un ejemplo de pipeline disponible en la documentación de Scrapy. En consecuencia, el fichero pipelines.py quedaría de la siguiente manera:
import pymongo
from itemadapter import ItemAdapter
class MongoPipeline:
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert_one(ItemAdapter(item).asdict())
return item
En la variable collection_name le indicamos el nombre de la colección donde vamos a almacenar los documentos con los datos.
Además, no debemos olvidarnos de indicar en el fichero de ajustes (settings.py) de Scrapy, por un lado, la ruta y el nombre de nuestro pipeline, y por otro lado, el nombre de nuestra base de datos y la dirección de MongoDB. Para ello, debéis añadir en el fichero las siguientes líneas con la información de vuestra base de datos y del pipeline:
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'zara.pipelines.MongoPipeline': 300,
}
MONGO_URI = 'mongodb://localhost:27017'
MONGO_DATABASE = 'nombre-db'
Cambiando el agente de usuario para evitar bloqueos
Algunos sitios web tienen mecanismos anti-rastreo, por lo que pueden bloquear el acceso de nuestra araña si detectan algún comportamiento sospechoso. Debido a ello y para evitar este tipo de situaciones, es recomendable cambiar el agente de usuario (user agent) con el que se identifica nuestra araña. De hecho, si intentáis utilizar el agente de usuario que viene por defecto para rastrear la web de Zara, veréis que al descargar las páginas no os devolverá más que códigos de error 404.
Así, podéis cambiar el agente de usuario de manera sencilla modificando la siguiente línea en el archivo settings.py:
# Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0"
En nuestro caso, nos estamos identificando como un navegador Mozilla Firefox con el sistema operativo Windows.
Una vez configurado este ajuste, ya estamos listos para ejecutar nuestra araña y comprobar los resultados.
Ejecutando nuestra araña
Para hacer funcionar a nuestra araña, debemos ejecutar el siguiente comando desde la carpeta del proyecto:
scrapy crawl zara
Una vez finalizado, en las últimas líneas del log del proceso se muestra diversa información interesante como el tiempo total del rastreo (elapsed_time_seconds) o el número de ítems rastreados (item_scraped_count).
2021-02-13 22:31:26 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 2259,
'downloader/request_count': 7,
'downloader/request_method_count/GET': 7,
'downloader/response_bytes': 359195,
'downloader/response_count': 7,
'downloader/response_status_count/200': 7,
'elapsed_time_seconds': 11.992025,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2021, 2, 13, 21, 31, 26, 467670),
'item_scraped_count': 7,
'log_count/DEBUG': 14,
'log_count/INFO': 11,
'response_received_count': 7,
'scheduler/dequeued': 7,
'scheduler/dequeued/memory': 7,
'scheduler/enqueued': 7,
'scheduler/enqueued/memory': 7,
'start_time': datetime.datetime(2021, 2, 13, 21, 31, 14, 475645)}
Por último, solo nos queda comprobar que, en efecto, los datos de las prendas de ropa se han insertado correctamente en nuestra colección de MongoDB. Para realizar la comprobación, entramos en el GUI Robo 3T y realizamos la consulta correspondiente. A continuación, podemos ver el resultado:
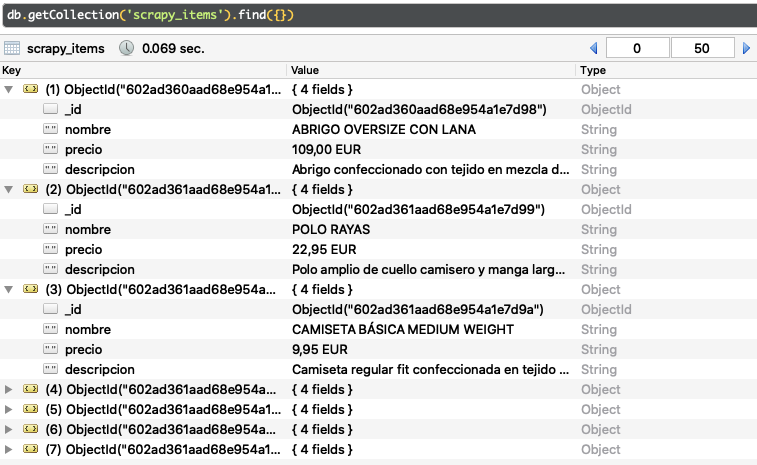
Productos insertados en MongoDB
Como se puede observar en la imagen, los siete productos de ropa se han insertado con éxito en la colección, cada uno en un documento distinto con su nombre, precio y descripción.
En este tutorial hemos aprendido como extraer la información de una serie de URLs seleccionadas del sitio web de Zara, pero ¿No sería fantástico poder obtener los datos de absolutamente todas o gran parte de las páginas que componen un dominio dado?
En la siguiente publicación de esta serie explicaremos como hacer que nuestra araña extraiga y navegue a través de los enlaces de las páginas de nuestro interés de manera iterativa hasta que rastré todo el dominio o un número máximo establecido de páginas.
Como siempre recordar que podéis obtener el código utilizado en este tutorial en nuestra cuenta de Github. ¡Hasta la próxima!


















