El sesgo en estadística es un problema omnipresente que puede invalidar los resultados de cualquier análisis, desde encuestas simples hasta modelos de aprendizaje automático complejos. Identificar y manejar el sesgo es crucial para garantizar que las conclusiones extraídas de los datos sean precisas y confiables. En este artículo, exploraremos en detalle qué es el sesgo, los diferentes tipos que existen, cómo podemos detectarlos y las estrategias para mitigar su impacto. Con ejemplos prácticos y casos de estudio, te guiaremos para que puedas aplicar estos conocimientos en tus propios proyectos de análisis de datos.
¿Qué es el Sesgo en Estadística?
El sesgo en estadística se refiere a cualquier desviación sistemática entre el resultado verdadero y el resultado obtenido en un estudio. No es simplemente un error aleatorio, sino una tendencia consistente que afecta la validez de las conclusiones. Esta desviación puede surgir de diversas fuentes, incluyendo el diseño del estudio, la recolección de datos, el análisis y la interpretación de los resultados.
Un ejemplo sencillo sería una encuesta sobre preferencias políticas realizada exclusivamente en un barrio con una fuerte inclinación hacia un partido específico. Los resultados de esta encuesta no serían representativos de la población general y estarían sesgados hacia las opiniones de los residentes de ese barrio.
Es importante distinguir entre sesgo y varianza. El sesgo se refiere a la exactitud (qué tan cerca está el resultado del valor verdadero), mientras que la varianza se refiere a la precisión (qué tan consistentes son los resultados entre diferentes muestras). Idealmente, queremos modelos con bajo sesgo y baja varianza.
Tipos de Sesgo y Ejemplos
Existen diversos tipos de sesgo que pueden afectar un análisis estadístico. A continuación, exploraremos algunos de los más comunes:
1. Sesgo de Selección: Ocurre cuando la muestra no es representativa de la población que se pretende estudiar. Esto puede suceder por varias razones, como el muestreo no aleatorio o la exclusión de ciertos grupos de la población.
Ejemplo: Un estudio sobre la salud de los ancianos que recluta participantes solo de centros de jubilados. Los resultados pueden no ser aplicables a todos los ancianos, ya que aquellos que no participan en centros de jubilados pueden tener características diferentes.
2. Sesgo de Información: Se produce cuando hay errores en la forma en que se miden o registran los datos. Esto puede incluir errores de medición, sesgo del observador (cuando el investigador influye en los resultados) y sesgo de recuerdo (cuando los participantes recuerdan información de manera inexacta).
Ejemplo: En una encuesta sobre consumo de alcohol, los participantes pueden subestimar la cantidad que beben debido a la deseabilidad social.
3. Sesgo de Confirmación: Es la tendencia a buscar, interpretar y recordar información que confirma las propias creencias o hipótesis, ignorando la evidencia que las contradice.
Ejemplo: Un investigador que cree firmemente en la eficacia de un determinado tratamiento puede interpretar los resultados de manera que favorezcan su hipótesis, incluso si los datos no son concluyentes.
4. Sesgo de Publicación: Ocurre cuando los estudios con resultados positivos (es decir, que muestran un efecto significativo) tienen más probabilidades de ser publicados que los estudios con resultados negativos o nulos.
Ejemplo: En la investigación farmacéutica, es más probable que se publiquen los estudios que demuestran la eficacia de un nuevo medicamento que los estudios que no lo hacen, lo que puede dar una impresión sesgada de la verdadera eficacia del medicamento.
5. Sesgo de Supervivencia: Se produce cuando se ignora a los individuos o entidades que no «sobrevivieron» a un determinado proceso, lo que puede llevar a conclusiones erróneas.
Ejemplo: Analizar el éxito de las empresas que siguen activas después de 10 años puede dar una visión demasiado optimista de las probabilidades de éxito empresarial, ya que no se tienen en cuenta las empresas que fracasaron.
Métodos para Corregir el Sesgo
Afortunadamente, existen métodos para corregir o mitigar el sesgo en los análisis estadísticos. Algunos de los más comunes son:
1. Re-muestreo y Ponderación: Si el sesgo es causado por una muestra no representativa, se pueden utilizar técnicas de re-muestreo para ajustar los datos y hacerlos más representativos de la población. La ponderación implica asignar diferentes pesos a diferentes observaciones para compensar las diferencias en la probabilidad de selección.
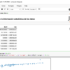
Ejemplo (Python):
import pandas as pd
from sklearn.utils import resample
# Supongamos que tenemos un DataFrame con una columna 'grupo' que está desbalanceada
data = pd.DataFrame({'grupo': ['A'] * 70 + ['B'] * 30})
# Realizamos un re-muestreo para equilibrar los grupos
data_a = data[data['grupo'] == 'A']
data_b = data[data['grupo'] == 'B']
# Submuestreamos la clase mayoritaria (A) para que coincida con el tamaño de la clase minoritaria (B)
data_a_downsampled = resample(data_a, replace=False, n_samples=len(data_b), random_state=123)
# Combinamos la clase minoritaria original con la clase mayoritaria submuestreada
data_balanced = pd.concat([data_a_downsampled, data_b])
print(data_balanced['grupo'].value_counts())
2. Análisis de Sensibilidad: Consiste en evaluar cómo los resultados de un análisis cambian cuando se modifican ciertos supuestos o parámetros. Esto puede ayudar a identificar qué tan sensibles son los resultados al sesgo y a determinar qué tan robustas son las conclusiones.
3. Uso de Modelos Estadísticos Robustos: Algunos modelos estadísticos son menos sensibles al sesgo que otros. Por ejemplo, los modelos no paramétricos (que no hacen supuestos sobre la distribución de los datos) pueden ser más robustos que los modelos paramétricos.
4. Recolección de Datos Cuidadosa: La mejor manera de combatir el sesgo es prevenirlo en primer lugar. Esto implica diseñar estudios cuidadosamente, utilizar métodos de muestreo aleatorio, capacitar a los recolectores de datos para minimizar el sesgo del observador y validar los datos para detectar errores.
5. Meta-análisis y Revisión Sistemática: En la investigación científica, el meta-análisis y la revisión sistemática son técnicas que combinan los resultados de múltiples estudios para obtener una estimación más precisa del efecto verdadero. Estas técnicas pueden ayudar a identificar y corregir el sesgo de publicación.
6. Calibración del Modelo: En el contexto del aprendizaje automático, la calibración se refiere a la capacidad de un modelo para proporcionar probabilidades bien calibradas, es decir, probabilidades que reflejen con precisión la probabilidad real de un evento. Existen técnicas para calibrar modelos y corregir el sesgo en sus predicciones.
Casos Prácticos en Ciencia de Datos
El sesgo puede tener un impacto significativo en la ciencia de datos. Aquí presentamos algunos casos prácticos:
1. Sistemas de Recomendación: Los algoritmos de recomendación, como los utilizados por Netflix o Amazon, pueden perpetuar el sesgo si se basan en datos históricos que reflejan patrones discriminatorios. Por ejemplo, si un sistema de recomendación de empleo se basa en datos históricos que muestran que las mujeres están subrepresentadas en ciertos campos, puede recomendar menos oportunidades de empleo a las mujeres.
Solución: Utilizar técnicas de aprendizaje automático justas (fair machine learning) para detectar y mitigar el sesgo en los algoritmos de recomendación.
2. Reconocimiento Facial: Los sistemas de reconocimiento facial han demostrado ser menos precisos para personas de ciertas razas y géneros. Esto puede tener consecuencias graves en aplicaciones como la seguridad y la justicia penal.
Solución: Recolectar conjuntos de datos más diversos y utilizar técnicas de entrenamiento que sean robustas al sesgo.
3. Diagnóstico Médico: Los algoritmos de diagnóstico médico pueden estar sesgados si se entrenan con datos que no son representativos de la población general. Por ejemplo, un algoritmo para detectar enfermedades cardíacas puede ser menos preciso para las mujeres si se entrena principalmente con datos de hombres.
Solución: Asegurarse de que los conjuntos de datos de entrenamiento sean diversos y representativos de la población a la que se aplicará el algoritmo.
4. Predicción de Riesgo Crediticio: Los modelos de predicción de riesgo crediticio pueden discriminar a ciertos grupos si se basan en variables que están correlacionadas con la raza o el género. Por ejemplo, el código postal puede ser un factor de riesgo que indirectamente discrimine a las personas que viven en barrios de bajos ingresos.
Solución: Eliminar variables que sean proxies de la raza o el género y utilizar técnicas de aprendizaje automático justas para detectar y mitigar el sesgo.
Identificar y manejar el sesgo en estadística es un proceso continuo que requiere atención y rigor. No existe una solución única para todos los tipos de sesgo, pero al comprender los diferentes tipos, las fuentes y las estrategias para mitigarlos, podemos mejorar la validez y la confiabilidad de nuestros análisis de datos. En última instancia, la lucha contra el sesgo es fundamental para garantizar que los datos se utilicen de manera justa y equitativa.