Apache Spark se ha consolidado como una de las herramientas más importantes para el procesamiento de datos a gran escala. Con cada nueva versión, Spark introduce mejoras significativas que impactan directamente en la eficiencia y capacidad de los Data Engineers. En este artículo, exploraremos en detalle las novedades y mejoras clave que ofrece Spark 3.x, centrándonos en los aspectos más relevantes para los profesionales que trabajan con datos.
Desde optimizaciones en el rendimiento hasta la compatibilidad con nuevos formatos de datos y funcionalidades mejoradas, Spark 3.x representa un salto cualitativo que permite abordar desafíos cada vez más complejos en el mundo del Big Data. Acompáñanos en este recorrido para descubrir cómo puedes aprovechar al máximo las nuevas características de Spark 3.x en tus proyectos.
Principales cambios en Spark 3.x
Spark 3.x introduce una serie de cambios fundamentales que mejoran significativamente la experiencia del usuario y la eficiencia del procesamiento de datos. Algunos de los cambios más destacados incluyen:
Adaptive Query Execution (AQE): Una de las características más importantes es la Adaptive Query Execution (AQE), que permite a Spark optimizar dinámicamente los planes de consulta en tiempo de ejecución. Esto significa que Spark puede ajustar el plan de ejecución en función de las estadísticas de los datos reales, lo que a menudo conduce a mejoras significativas en el rendimiento.
Dynamic Partition Pruning: El Dynamic Partition Pruning (DPP) es otra mejora clave que ayuda a reducir la cantidad de datos escaneados durante la ejecución de las consultas. DPP permite a Spark filtrar particiones innecesarias basándose en los valores reales de los datos, lo que puede resultar en un rendimiento mucho más rápido para ciertas cargas de trabajo.
ANSI SQL Compliance: Spark 3.x mejora su compatibilidad con el estándar ANSI SQL, lo que facilita la migración de cargas de trabajo SQL existentes a Spark y proporciona una experiencia más consistente para los usuarios que están familiarizados con SQL.
Photon: Introducción de Photon, un motor de consulta vectorizado nativo escrito en C++, que ofrece un rendimiento significativamente mejorado para las cargas de trabajo de Spark SQL. Photon está diseñado para aprovechar al máximo las capacidades de hardware modernas y puede proporcionar mejoras de rendimiento de hasta 2x en comparación con el motor de consulta basado en JVM.
Mejoras en optimización y rendimiento
Las mejoras en optimización y rendimiento son un foco central de Spark 3.x, y se manifiestan en varias áreas clave:
Join Optimization: Spark 3.x introduce mejoras significativas en la optimización de joins, incluyendo la capacidad de elegir automáticamente la estrategia de join más eficiente en función del tamaño de los datos y otras características. Esto puede resultar en mejoras sustanciales en el rendimiento de las consultas que involucran joins.
Codegen Optimization: La optimización de la generación de código (codegen) se ha mejorado en Spark 3.x para generar código más eficiente y optimizado para la ejecución de consultas. Esto puede resultar en mejoras en el rendimiento de las consultas, especialmente para las cargas de trabajo que involucran cálculos complejos.
Predicate Pushdown: Spark 3.x mejora el predicate pushdown, lo que permite a Spark filtrar los datos lo más cerca posible de la fuente de datos. Esto puede resultar en una reducción significativa en la cantidad de datos que deben ser leídos y procesados, lo que a su vez mejora el rendimiento.
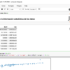
Ejemplo de mejora en rendimiento con AQE:
-- Desactivar AQE (por defecto está activado)
SET spark.sql.adaptive.enabled = false;
-- Ejecutar consulta sin AQE
SELECT count(*) FROM orders WHERE order_date = '2024-01-01';
-- Activar AQE
SET spark.sql.adaptive.enabled = true;
-- Ejecutar la misma consulta con AQE
SELECT count(*) FROM orders WHERE order_date = '2024-01-01';Comparando los tiempos de ejecución, se puede observar una mejora significativa con AQE activado, especialmente en joins complejos y agregaciones.
Compatibilidad con nuevos formatos de datos
Spark 3.x amplía su compatibilidad con una variedad de formatos de datos nuevos y mejorados, lo que facilita la integración con diferentes fuentes de datos y sistemas de almacenamiento:
Parquet Enhancements: Spark 3.x introduce mejoras en la lectura y escritura de archivos Parquet, incluyendo soporte para nuevas características como el predicate pushdown y el column pruning. Esto puede resultar en mejoras significativas en el rendimiento de las cargas de trabajo que involucran archivos Parquet.
ORC Enhancements: De manera similar, Spark 3.x también introduce mejoras en la lectura y escritura de archivos ORC, incluyendo soporte para nuevas características como el vectorized reader. Esto puede resultar en mejoras significativas en el rendimiento de las cargas de trabajo que involucran archivos ORC.
Avro Enhancements: Spark 3.x también mejora el soporte para el formato Avro, incluyendo soporte para esquemas evolucionados y la capacidad de leer y escribir archivos Avro comprimidos. Esto facilita el trabajo con datos Avro y permite una mayor flexibilidad en el diseño de esquemas.
JSON Enhancements: El soporte para JSON también se ha mejorado, permitiendo un mejor manejo de datos semi-estructurados y facilitando la integración con APIs y servicios web.
Ejemplos de código y casos de uso
Para ilustrar las capacidades de Spark 3.x, veamos algunos ejemplos de código y casos de uso:
Ejemplo de Adaptive Query Execution (AQE):
# Ejemplo de cómo AQE optimiza un join
df1 = spark.read.parquet("path/to/large/parquet/file")
df2 = spark.read.csv("path/to/small/csv/file", header=True)
# Spark optimizará el join dinámicamente usando BroadcastHashJoin si df2 es lo suficientemente pequeño
df1.join(df2, df1.id == df2.id).count()En este ejemplo, Spark puede decidir dinámicamente usar un BroadcastHashJoin si df2 es lo suficientemente pequeño, optimizando así el rendimiento del join.
Ejemplo de Dynamic Partition Pruning (DPP):
# Ejemplo de cómo DPP reduce la cantidad de datos escaneados
df_orders = spark.read.table("orders")
df_customers = spark.read.table("customers")
# DPP filtra las particiones de df_orders basadas en los valores de df_customers
df_orders.join(df_customers, df_orders.customer_id == df_customers.id).filter(df_customers.country == "USA").count()Aquí, DPP permite a Spark filtrar particiones innecesarias en df_orders basadas en los valores de df_customers.country, reduciendo así la cantidad de datos escaneados.
Caso de uso: Procesamiento de logs a gran escala:
Una empresa puede usar Spark 3.x para procesar logs de servidores web a gran escala. Con las mejoras en el rendimiento y la compatibilidad con diferentes formatos de datos, Spark 3.x puede procesar los logs de manera más eficiente y extraer información valiosa para la toma de decisiones.
Spark 3.x representa una evolución significativa en el ecosistema de procesamiento de datos a gran escala. Las mejoras en la optimización del rendimiento, la compatibilidad con nuevos formatos de datos y las nuevas funcionalidades como Adaptive Query Execution y Dynamic Partition Pruning hacen de Spark 3.x una herramienta poderosa para los Data Engineers.
Al adoptar Spark 3.x, las organizaciones pueden mejorar la eficiencia de sus procesos de datos, reducir los costos y obtener información valiosa de sus datos de manera más rápida y sencilla. La continua evolución de Spark garantiza que seguirá siendo una herramienta clave en el mundo del Big Data en los años venideros.