Extracción de datos de sitios web con Scrapy (II): rastreando todas las URLs del sitio web de Zara
En la anterior publicación de la serie dedicada al web scraping en Python con Scrapy, explicamos paso a paso como extraer (con el framework Scrapy) la información de un conjunto de páginas web (seleccionadas por nosotros) de forma automatizada, para finalmente almacenarla en un sistema de almacenamiento MongoDB.
En ese mismo artículo, comentábamos que una de las grandes limitaciones de nuestra araña consistía en que solo estábamos rastreando y extrayendo los datos de la lista de páginas seleccionadas previamente.
Sin embargo, existen ocasiones donde nos interesa rastrear y obtener los datos de todas las páginas que componen un sitio web, y eso es precisamente lo que explicaremos en el post de hoy.
A grandes rasgos, el objetivo consiste en hacer que nuestra araña extraiga y navegue a través de los enlaces de las páginas de nuestro interés de manera iterativa hasta que consiga rastrear todo el dominio o un número máximo establecido de páginas.
Pero, antes de nada, nos conviene recordar el sitio web que utilizaremos en este tutorial.
Sitio web de Zara
Para este tutorial continuamos donde los dejamos en la anterior publicación, y, por lo tanto, usaremos de nuevo el sitio web de Zara, donde nos centramos en recopilar el nombre, el precio y la descripción de cada producto.
No obstante, en esta publicación nos enfocaremos únicamente en las páginas en su versión española, que en el caso de Zara están alojadas en el subdominio /es/.
Así, ampliaremos el código de nuestro proyecto con el fin de construir un rastreador que extraiga de manera recursiva los enlaces de las páginas e igualmente recopile la información de esos enlaces extraídos.
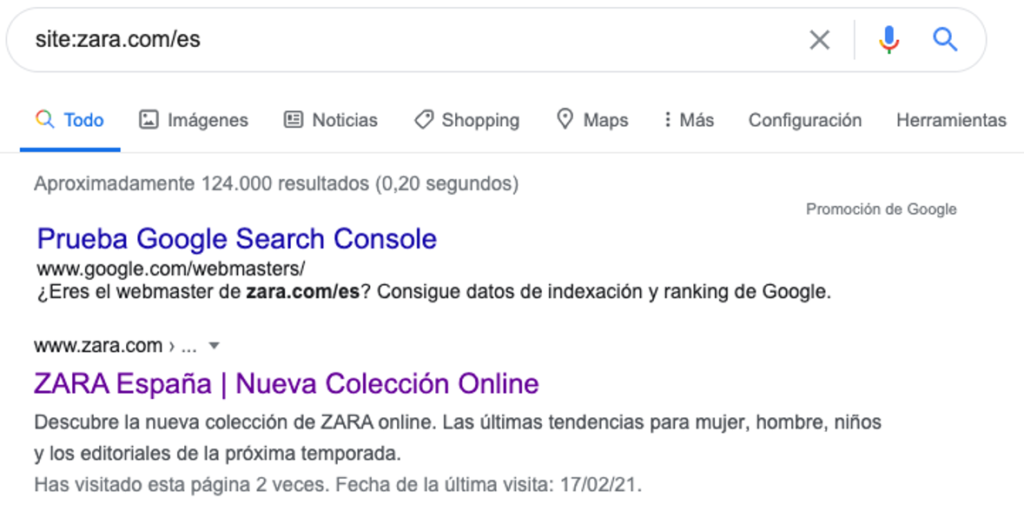
Antes de comenzar, recomendamos conocer el número de páginas que tiene el sitio web que pretendemos rastrear, ya que el plan es que nuestra araña las recorra todas y cada una de ellas. Una manera muy fácil de obtener el número de páginas aproximadas que tiene un dominio consiste en escribir el buscador de Google el comando site: seguido del nombre del sitio, por ejemplo site:elpais.com. En la siguiente imagen se muestra el resultado al utilizar este comando con el sitio de Zara.
Búsqueda de resultados en Google con comando site
Como se muestra en la anterior imagen, el dominio de Zara en su versión española cuenta con alrededor de 124.000 URLs.
Modificando el número de URLs a rastrear y otros ajustes
En nuestro caso, vamos a rastrear todas las páginas de Zara, pero si no podeis esperar a que el rastreador termine de recorrer y descargar las 124.000 URLs o simplemente no necesitáis un número tan alto de URLs, podéis limitar el número máximo de respuestas que puede rastrear la araña. Para ello, sencillamente añadimos en el fichero settings.py el ajuste CLOSESPIDER_PAGECOUNT:
CLOSESPIDER_PAGECOUNT = 10000
Con la anterior expresión conseguiremos que la araña finalice en cuanto haya rastreado más de 10.000 páginas.
Además, para evitar ser bloqueado en caso de que el sitio web cuente con métodos anti-rastreo, una buena práctica consiste en disminuir la velocidad de la araña introduciendo para ello retrasos de tiempo entre las peticiones.
En este caso, haremos uso de la variable DOWNLOAD_DELAY, que nos permitirá definir los segundos que nuestra araña debe esperar antes de descargar páginas consecutivas del mismo sitio web. En esta ocasión definimos un retraso de 2 segundos introduciendo como siempre la siguiente línea en el fichero de configuración.
CLOSESPIDER_PAGECOUNT = 2
Además, si leísteis la anterior publicación sobre Scrapy, recordaréis que otro de los consejos para evitar ser bloquedados al rastrear, consiste en cambiar el agente de usuario (User Agent) con el que se identifica el rastreador. Esto lo conseguimos insertando la siguiente línea en el fichero settings.py:
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0"
De esta manera nos estamos identificando como un navegador Mozilla Firefox con el sistema operativo Windows.
Una vez hemos añadido estos dos nuevos ajustes, estamos listos para extraer los enlaces.
Extrayendo enlaces de cada URL con LinkExtractor
Gracias al objeto LinkExtractor que nos provee Scrapy, conseguiremos extraer los enlaces de cada respuesta. Algunos de los parámetros de interés que nos encontramos en el objeto LinkExtractor y que utilizaremos en este ejemplo, son los siguientes:
allow_domains: indica el dominio o lista de dominios que se tendrán en cuenta a la hora de extraer los enlaces. Para el caso que nos ocupa, le pasaremos únicamente el dominio zara.com.restrict_xpaths: XPath (o lista de XPaths) que define las regiones dentro de la respuesta de donde se deben extraer los enlaces. En esta ocasión utilizaremos la expresión//acon la que conseguiremos extraer todos los enlaces de Zara, pero podríamos especificar una región más concreta de la página.allow: expresión regular (o lista de expresiones regulares) con la que debe coincidir las URLs absolutas para poder ser extraídas. Aprovecharemos este parámetro para indicar que solo queremos almacenar las páginas de España, es decir, las que se alojen en el subdirectorio /es/.
Podéis acceder a la documentación oficial aquí, donde encontrareis el resto de parámetros disponibles.
Seguidamente mostramos la parte del código donde construimos el objeto LinkExtractor y extraemos los enlaces en nuestro proyecto:
# Extraemos los enlaces
links = LinkExtractor(
allow_domains=['zara.com'],
restrict_xpaths=["//a"],
allow="/es/"
).extract_links(response)
El siguiente paso es recorrer todos los enlaces extraídos y generar una petición (Request) por cada uno de ellos. En el parámetro callback de la petición le indicamos la función que será llamada pasándole la página descargada, en este caso parse.
Para este ejemplo, aparte de la información de los productos (precio, nombre y descripción), también vamos a almacenar la dirección URL de cada página y sus enlaces, por lo que almacenaremos estos enlaces en un array para posteriormente insertarlos en nuestra base de datos. Esta parte de código tiene el siguiente aspecto:
outlinks = [] # Lista con todos los enlaces
for link in links:
url = link.url
outlinks.append(url) # Añadimos el enlace en la lista
yield Request(url, callback=self.parse) # Generamos la petición
Ya sólo nos queda un último paso donde vamos a ampliar nuestro método parse con el fin de evitar almacenar aquellas URLs que no sean de producto. Si nos fijamos, todas las páginas de producto tienen en común (en su código HTML) la etiqueta meta og:type con el atributo content igual a product. Esta información nos será de mucha utilizad para construir una expresión XPath que nos permita identificar las URLs que contengan esta etiqueta y de esta forma excluir al resto.
Finalmente juntamos todas las piezas y mostramos como quedaría el método parse al completo:
def parse(self, response):
producto = Producto()
# Extraemos los enlaces
links = LinkExtractor(
allow_domains=['zara.com'],
restrict_xpaths=["//a"],
allow="/es/"
).extract_links(response)
outlinks = [] # Lista con todos los enlaces
for link in links:
url = link.url
outlinks.append(url) # Añadimos el enlace en la lista
yield Request(url, callback=self.parse) # Generamos la petición
product = response.xpath('//meta[@content="product"]').extract()
if product:
# Extraemos la url, el nombre del producto, la descripcion y su precio
producto['url'] = response.request.url
producto['nombre'] = response.xpath('//h1[@class="product-detail-info__name"]/text()').extract_first()
producto['precio'] = response.xpath('//span[@class="price__amount"]/text()').extract_first()
producto['descripcion'] = response.xpath('//div[@class="expandable-text product-detail-info__description"]//text()').extract_first()
producto['links'] = outlinks
yield producto
Ejecutando nuestra araña
Hacemos funcionar a nuestra araña ejecutando el siguiente comando desde la carpeta del proyecto:
scrapy crawl zara
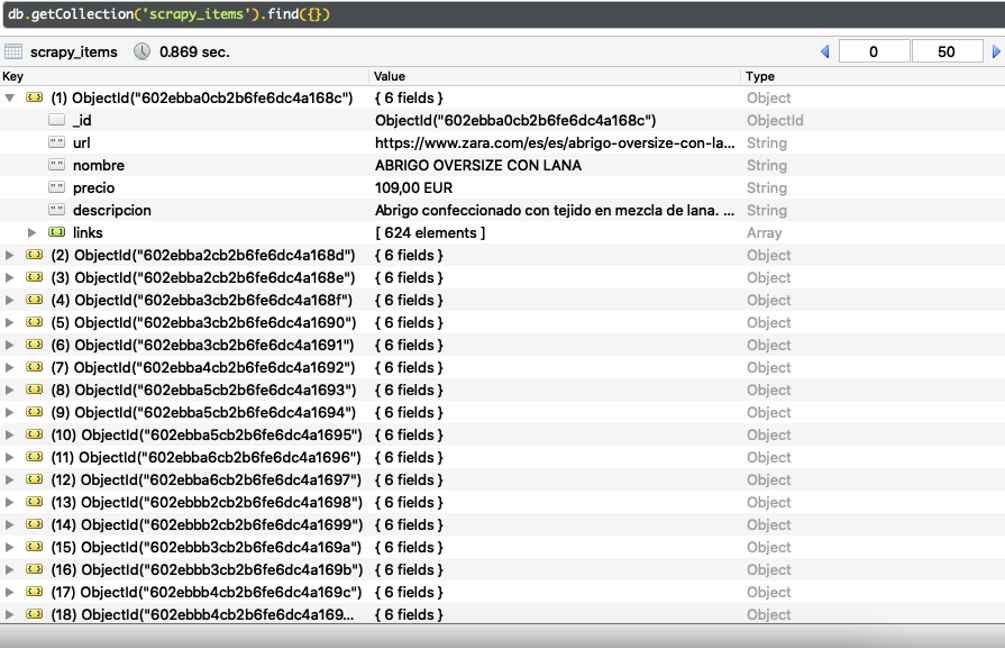
Por último, revisamos que, en efecto, los datos de las prendas de ropa, las URLs y los enlaces se han insertado de manera exitosa en nuestra colección de MongoDB. Al igual que en anterior publicación, realizamos la comprobación con el GUI Robo 3T. Debajo podemos ver el resultado:
Productos de Zara almacenados en MongoDB
Claramente vemos que se han insertado correctamente las páginas de productos de ropa junto con su nombre, precio, descripción, URL y enlaces.
Con este post, hemos aprendido como rastrear y extraer la información de todas las páginas que componen un sitio web. Esperamos que haya sido de utilizad.
Para más información recordar que tenéis disponible todo el código usado en este tutorial desde nuestra cuenta de GitHub y si tienes cualquier duda, nos la podéis hacer llegar a través de los comentarios.
A continuación tenéis todas las publicaciones de esta serie hasta ahora: